Hadoop 2.7.1 实现HA集群部署
1.0 简述
Hadoop 2.0中的HDFS增加了两个重大特性,HA和Federation,HA即为High Availability,用于解决NameNode单点故障问题,该特性通过热备的方式为主NameNode提供一个备用者,一旦主NameNode出现故障,可以迅速切换至备NameNode,从而实现不间断对外提供服务。Federation即为“联邦”,该特性允许一个HDFS集群中存在多个NameNode同时对外提供服务,这些NameNode分管一部分目录(水平切分),彼此之间相互隔离,但共享底层的DataNode存储资源。本文就讲如何安装Hadoop 2.7.1 实现HA集群。联邦的安装部署我们将在下次讲。
1.1 主机列表
| IP | NAME | Function |
|---|---|---|
| 192.168.199.24 | hadoop24.hadoop.com | 主namenode,zookeeper,journalnode,zkfc,ResourceManager |
| 192.168.199.25 | hadoop25.hadoop.com | 备namenode,zookeepaer,journalnode,zkfc |
| 192.168.199.26 | hadoop26.hadoop.com | datanode,zookeepaer,journalnode,NodeManager |
| 192.168.199.27 | hadoop27.hadoop.com | Datanode,NodeManager |
| 192.168.199.28 | hadoop28.hadoop.com | Datanode,NodeManager |
1.2 Zookeeper安装配置
下载Zookeeper并安装配置
#tar -xzvf zookeeper-3.4.6.tar.gz
#cd zookeeper-3.4.6/conf
#cp zoo_sample.cfg zoo.cfg
#vi zoo.cfg
dataDir=/home/grid/zookeeper-3.4.6/data
server.1=hadoop24.hadoop.com:2888:3888
server.2=hadoop25.hadoop.com:2888:3888
server.3=hadoop26.hadoop.com:2888:3888
#cd ..
#mkdir data
#cd ..
生成分发脚本,并执行
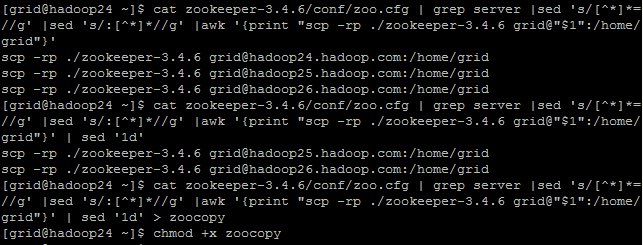
#cat zookeeper-3.4.6/conf/zoo.cfg | grep server |sed 's/[^*]*=//g' |sed 's/:[^*]*//g' |awk '{print "scp -rp ./zookeeper-3.4.6 grid@"$1":/home/grid"}' | sed '1d' > zoocopy
#./zoocopy
在hadoop24上
#echo "1" > ~/zookeeper-3.4.6/data/myid
在hadoop25上
#echo "2" > ~/zookeeper-3.4.6/data/myid
在hadoop26上
#echo "3" > ~/zookeeper-3.4.6/data/myid
在每台上执行启动
#~/zookeeper-3.4.6/bin/zkServer.sh start

查看状态
#~/zookeeper-3.4.6/bin/zkServer.sh status
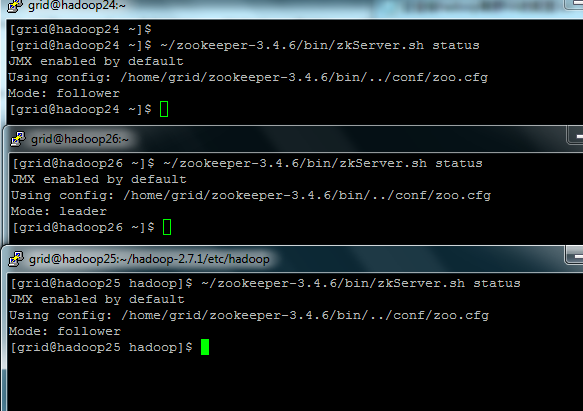
可以看到一台leader,两台follower
1.3 Hadoop安装配置
下载hadoop 2.7.1并解压
#tar -xzvf hadoop-2.7.1.tar.gz
#cd hadoop-2.7.1
#mkdir name data tmp journal
#cd etc/Hadoop
设置JAVA_HOME路径
#vi hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_51
#vi yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_51
编辑slaves文件
#vi slaves
hadoop26.hadoop.com
hadoop27.hadoop.com
hadoop28.hadoop.com
编辑core-site文件
#vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/grid/hadoop-2.7.1/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.199.24:2181,192.168.199.25:2181,192.168.199.26:2181</value>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>1000</value>
</property>
</configuration>
编辑mapred-site文件
#vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
编辑yarn-site文件
#vi yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop24.hadoop.com:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop24.hadoop.com:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop24.hadoop.com:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop24.hadoop.com:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop24.hadoop.com:8088</value>
</property>
</configuration>
编辑hdfs-site文件
#vi hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/grid/hadoop-2.7.1/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/grid/hadoop-2.7.1/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop24.hadoop.com:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop25.hadoop.com:9000</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.mycluster.nn1</name>
<value>hadoop24.hadoop.com:53310</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.mycluster.nn2</name>
<value>hadoop25.hadoop.com:53310</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop24.hadoop.com:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop25.hadoop.com:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop24.hadoop.com:8485;hadoop25.hadoop.com:8485;hadoop26.hadoop.com:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/grid/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/grid/hadoop-2.7.1/journal</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
<property>
<name>ipc.client.connect.timeout</name>
<value>60000</value>
</property>
<property>
<name>dfs.image.transfer.bandwidthPerSec</name>
<value>4194304</value>
</property>
</configuration>
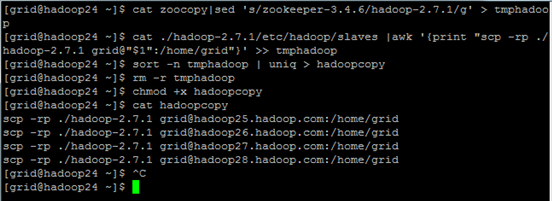
生成分发脚本
#cat zoocopy|sed 's/zookeeper-3.4.6/hadoop-2.7.1/g' > tmphadoop
#cat ./hadoop-2.7.1/etc/hadoop/slaves |awk '{print "scp -rp ./hadoop-2.7.1 grid@"$1":/home/grid"}' >> tmphadoop
#sort -n tmphadoop | uniq > hadoopcopy
#rm -r tmphadoop
#cat hadoopcopy
#./hadoopcopy
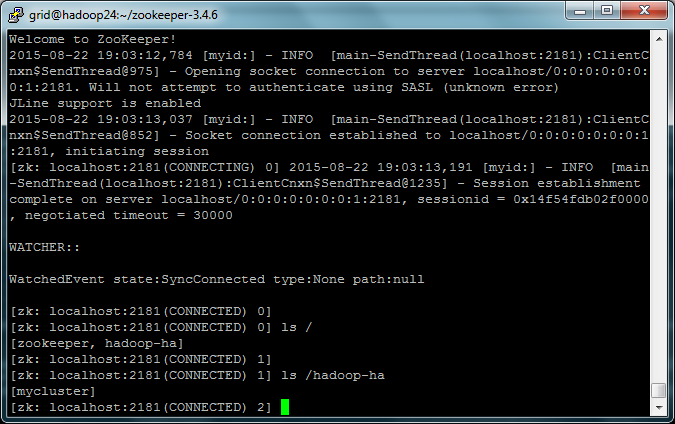
创建znode
#~/zookeeper-3.4.6/bin/zkServer.sh start
#~/hadoop-2.7.1/bin/hdfs zkfc -formatZK
验证
#~/zookeeper-3.4.6/bin/zkCli.sh
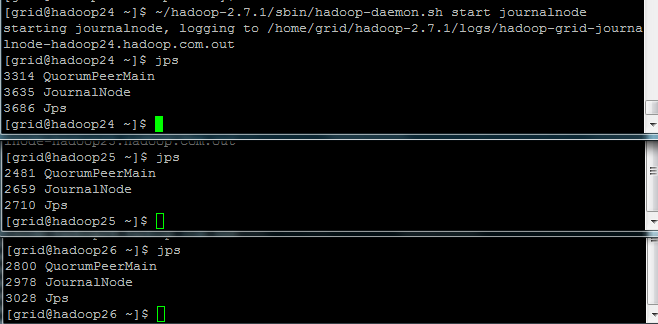
在hadoop24,hadoop25,hadoop26启动journalnode
#~/hadoop-2.7.1/sbin/hadoop-daemon.sh start journalnode
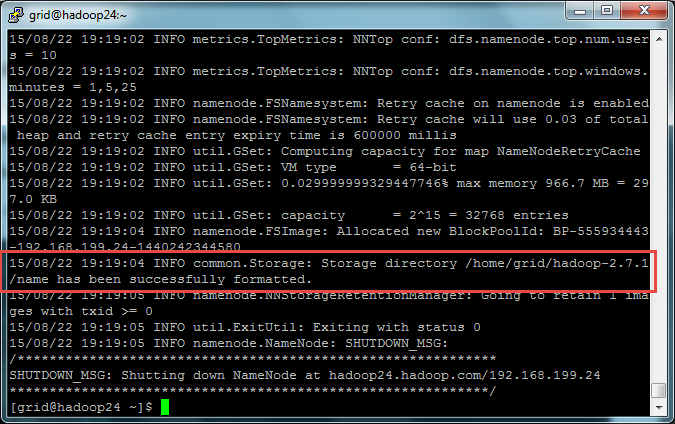
在主namenode节点(Hadoop24.hadoop.com)上格式化Namenode
#~/hadoop-2.7.1/bin/hadoop namenode –format
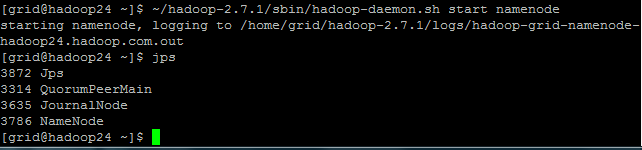
在主namenode节点(Hadoop24.hadoop.com)启动namenode进程
#~/hadoop-2.7.1/sbin/hadoop-daemon.sh start namenode
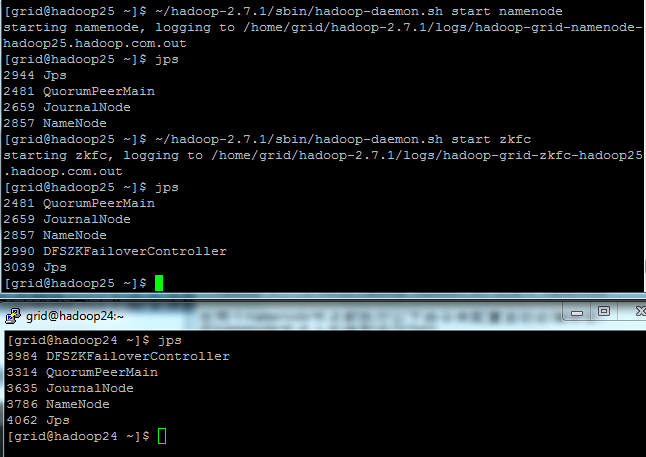
在备namenode节点(Hadoop25.hadoop.com)同步元数据
#~/hadoop-2.7.1/bin/hdfs namenode -bootstrapStandby
启动备NameNode节点(Hadoop25.hadoop.com)
#~/hadoop-2.7.1/sbin/hadoop-daemon.sh start namenode
在两个namenode节点都执行以下命令来配置自动故障转移:
在NameNode节点上安装和运行ZKFC
#~/hadoop-2.7.1/sbin/hadoop-daemon.sh start zkfc
启动datanode(hadoop26,hadoop27,hadoop28)
#~/hadoop-2.7.1/sbin/hadoop-daemons.sh start datanode
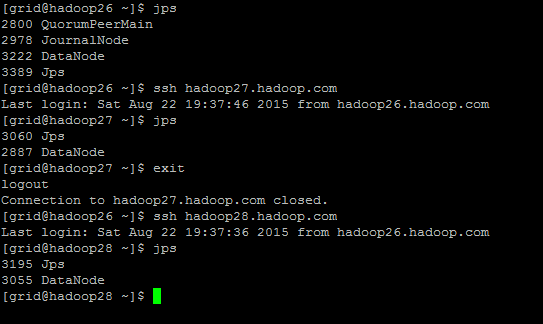
启动yarn
#~/hadoop-2.7.1/sbin/start-yarn.sh

主namenode节点上active
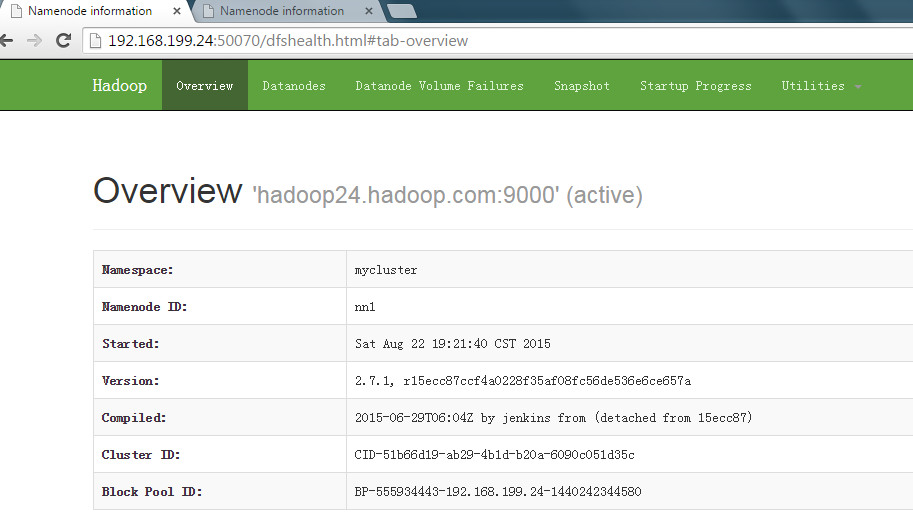
备namenode节点上standby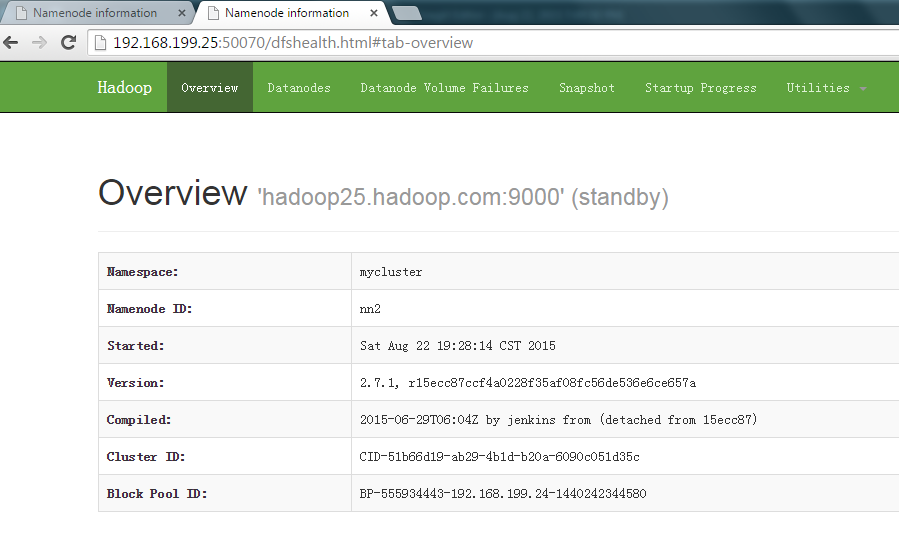 ]
]
1.4 验证HA
测试主备namenode节点是否工作,在主namenode机器上通过jps命令查找到namenode的进程号,然后通过kill -9的方式杀掉进程,观察另一个namenode节点是否会从状态standby变成active状态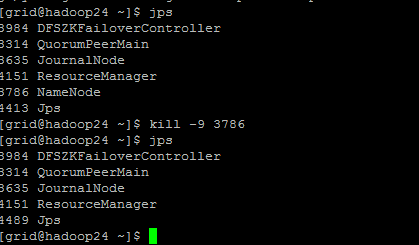
Kill进程后,主节点不能访问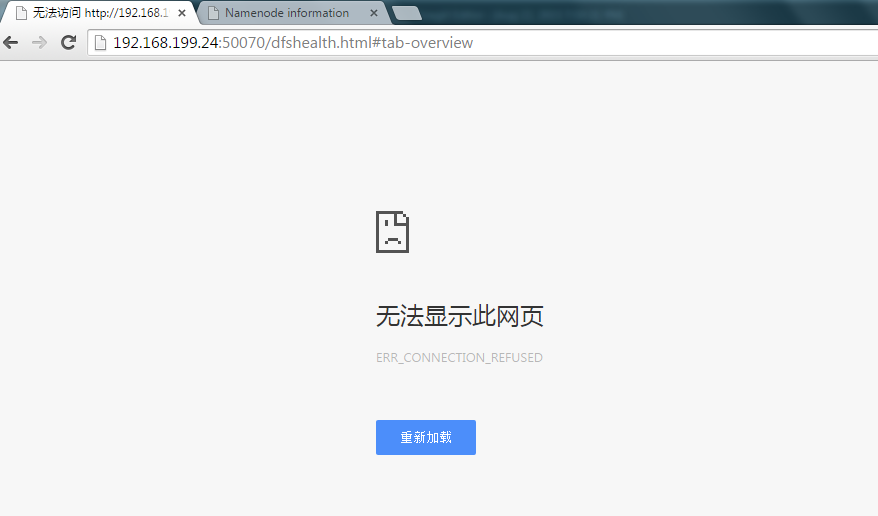
备节点已变为active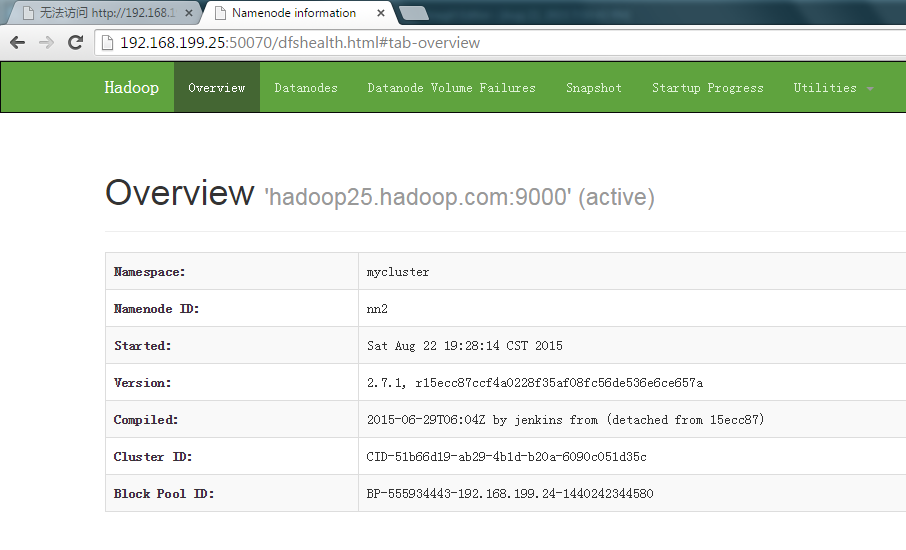
测试备节点能否继续工作
在备节点上测试
#~/hadoop-2.7.1/bin/hadoop fs -ls /
#~/hadoop-2.7.1/bin/hadoop fs -put /home/grid/test.txt /
#~/hadoop-2.7.1/bin/hadoop fs -cat /test.txt
#~/hadoop-2.7.1/bin/hadoop jar ~/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /test.txt /out
#~/hadoop-2.7.1/bin/hadoop fs -ls /out
#~/hadoop-2.7.1/bin/hadoop fs -cat /out/part-r-00000
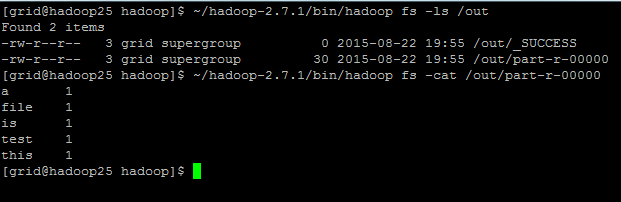
至此在Hadoop2.7.1集群上成功实现HA