Kafka入门之三:Kafka集群安装及演示
1. 简介
在Kafka入门之一:使用Docker安装Kafka和Zookeeper里我们已经演示使用docker安装单节点的Kafka,也就是一个broker。但实际上kafka是天生支持多broker的。在安装之前,我们先来看几个broker参数。 更多参数参见官网.
| Property | Default | Description |
| broker.id | 每个broker都可以用一个唯一的非负整数id进行标识;这个id可以作为broker的“名字”,并且它的存在使得broker无须混淆consumers就可以迁移到不同的host/port上。你可以选择任意你喜欢的数字作为id,只要id是唯一的即可。 | |
| log.dirs | /tmp/kafka-logs | kafka存放数据的路径。这个路径并不是唯一的,可以是多个,路径之间只需要使用逗号分隔即可;每当创建新partition时,都会选择在包含最少partitions的路径下进行。 |
| port | 9092 | server接受客户端连接的端口 |
| zookeeper.connect | null | ZooKeeper连接字符串的格式为:hostname:port,此处hostname和port分别是ZooKeeper集群中某个节点的host和port;为了当某个host宕掉之后你能通过其他ZooKeeper节点进行连接,你可以按照一下方式制定多个hosts:hostname1:port1, hostname2:port2, hostname3:port3.ZooKeeper 允许你增加一个“chroot”路径,将集群中所有kafka数据存放在特定的路径下。当多个Kafka集群或者其他应用使用相同ZooKeeper集群时,可以使用这个方式设置数据存放路径。这种方式的实现可以通过这样设置连接字符串格式,如下所示:hostname1:port1,hostname2:port2,hostname3:port3/chroot/path这样设置就将所有kafka集群数据存放在/chroot/path路径下。注意,在你启动broker之前,你必须创建这个路径,并且consumers必须使用相同的连接格式。 |
| message.max.bytes | 1000000 | server可以接收的消息最大尺寸。重要的是,consumer和producer有关这个属性的设置必须同步,否则producer发布的消息对consumer来说太大。 |
| num.network.threads | 3 | server用来处理网络请求的网络线程数目;一般你不需要更改这个属性。 |
| num.io.threads | 8 | server用来处理请求的I/O线程的数目;这个线程数目至少要等于硬盘的个数。 |
| background.threads | 4 | 用于后台处理的线程数目,例如文件删除;你不需要更改这个属性。 |
| queued.max.requests | 500 | 在网络线程停止读取新请求之前,可以排队等待I/O线程处理的最大请求个数。 |
| host.name | null | broker的hostname;如果hostname已经设置的话,broker将只会绑定到这个地址上;如果没有设置,它将绑定到所有接口,并发布一份到ZK |
| advertised.host.name | null | 如果设置,则就作为broker 的hostname发往producer、consumers以及其他brokers |
| advertised.port | null | 此端口将给与producers、consumers、以及其他brokers,它会在建立连接时用到; 它仅在实际端口和server需要绑定的端口不一样时才需要设置。 |
| num.partitions | 1 | 如果创建topic时没有给出划分partitions个数,这个数字将是topic下partitions数目的默认数值。 |
| auto.create.topics.enable | true | 是否允许自动创建topic。如果是真的,则produce或者fetch 不存在的topic时,会自动创建这个topic。否则需要使用命令行创建topic |
| default.replication.factor | 1 | 默认备份份数,仅指自动创建的topics |
| replica.lag.time.max.ms | 10000 | 如果一个follower在这个时间内没有发送fetch请求,leader将从ISR重移除这个follower,并认为这个follower已经挂了 |
| replica.lag.max.messages | 4000 | 如果一个replica没有备份的条数超过这个数值,则leader将移除这个follower,并认为这个follower已经挂了 |
| replica.socket.timeout.ms | 301000 | leader 备份数据时的socket网络请求的超时时间 |
| replica.socket.receive.buffer.bytes | 641024 | 备份时向leader发送网络请求时的socket receive buffer |
| replica.fetch.max.bytes | 1024*1024 | 备份时每次fetch的最大值 |
| replica.fetch.min.bytes | 500 | leader发出备份请求时,数据到达leader的最长等待时间 |
| replica.fetch.min.bytes | 1 | 备份时每次fetch之后回应的最小尺寸 |
| num.replica.fetchers | 1 | 从leader备份数据的线程数 |
| replica.high.watermark.checkpoint.interval.ms | 5000 | 每个replica检查是否将最高水位进行固化的频率 |
| zookeeper.session.timeout.ms | 6000 | zookeeper会话超时时间。 |
| zookeeper.connection.timeout.ms | 6000 | 客户端等待和zookeeper建立连接的最大时间 |
| zookeeper.sync.time.ms | 2000 | zk follower落后于zk leader的最长时间 |
| auto.leader.rebalance.enable | true | 如果这是true,控制者将会自动平衡brokers对于partitions的leadership |
| leader.imbalance.per.broker.percentage | 10 | 每个broker所允许的leader最大不平衡比率 |
| leader.imbalance.check.interval.seconds | 300 | 检查leader不平衡的频率 |
| offset.metadata.max.bytes | 4096 | 允许客户端保存他们offsets的最大个数 |
| max.connections.per.ip | Int.MaxValue | 每个ip地址上每个broker可以被连接的最大数目 |
| max.connections.per.ip.overrides | 每个ip或者hostname默认的连接的最大覆盖 | |
| connections.max.idle.ms | 600000 | 空连接的超时限制 |
| log.roll.jitter.{ms,hours} | 0 | 从logRollTimeMillis抽离的jitter最大数目 |
| num.recovery.threads.per.data.dir | 1 | 每个数据目录用来日志恢复的线程数目 |
| unclean.leader.election.enable | true | 指明了是否能够使不在ISR中replicas设置用来作为leader |
| delete.topic.enable | false | 能够删除topic |
这些参数在你还没有了解具体用途之前,你都可以默认,今天我们将会使用几个参数。
2. Kafka集群
2.1 Dockerfile
我们在dockeefile中加入一些broker的参数,即在server.properites文件中设置的参数。
FROM java:openjdk-8-jre-alpine
ARG MIRROR=http://mirrors.aliyun.com/
ARG SCALA_VERSION=2.11
ARG KAFKA_VERSION=0.8.2.2
LABEL name="kafka" version=$VERSION
RUN apk update && apk add ca-certificates && \
apk add tzdata && \
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \
echo "Asia/Shanghai" > /etc/timezone
RUN apk add --no-cache wget bash \
&& mkdir /opt \
&& wget -q -O - $MIRROR/apache/kafka/$KAFKA_VERSION/kafka_$SCALA_VERSION-$KAFKA_VERSION.tgz | tar -xzf - -C /opt \
&& mv /opt/kafka_$SCALA_VERSION-$KAFKA_VERSION /opt/kafka \
&& sed -i 's/num.partitions.*$/num.partitions=3/g' /opt/kafka/config/server.properties
RUN echo "cd /opt/kafka" > /opt/kafka/start.sh &&\
echo "sed -i 's%zookeeper.connect=.*$%zookeeper.connect=zookeeper:2181%g' /opt/kafka/config/server.properties" >> /opt/kafka/start.sh &&\
echo "[ ! -z $""BROKER_ID"" ] && sed -i 's%broker.id=.*$%broker.id='$""BROKER_ID'""%g' /opt/kafka/config/server.properties" >> /opt/kafka/start.sh &&\
echo "[ ! -z $""BROKER_PORT"" ] && sed -i 's%port=.*$%port='$""BROKER_PORT'""%g' /opt/kafka/config/server.properties" >> /opt/kafka/start.sh &&\
echo "sed -i 's%#advertised.host.name=.*$%advertised.host.name='$""(hostname -i)'""%g' /opt/kafka/config/server.properties" >> /opt/kafka/start.sh &&\
echo "[ ! -z $""ADVERTISED_HOST_NAME"" ] && sed -i 's%.*advertised.host.name=.*$%advertised.host.name='$""ADVERTISED_HOST_NAME'""%g' /opt/kafka/config/server.properties" >> /opt/kafka/start.sh &&\
echo "sed -i 's%#host.name=.*$%host.name='$""(hostname -i)'""%g' /opt/kafka/config/server.properties" >> /opt/kafka/start.sh &&\
echo "[ ! -z $""HOST_NAME"" ] && sed -i 's%.*host.name=.*$%host.name='$""HOST_NAME'""%g' /opt/kafka/config/server.properties" >> /opt/kafka/start.sh &&\
echo "delete.topic.enable=true" >> /opt/kafka/config/server.properties &&\
echo "bin/kafka-server-start.sh config/server.properties" >> /opt/kafka/start.sh &&\
chmod a+x /opt/kafka/start.sh
EXPOSE 9092
WORKDIR /opt/kafka
ENTRYPOINT ["sh", "/opt/kafka/start.sh"]
2.2 启动zookeeper
为简单起见,zookeeper我们暂时使用单个容器。
sudo docker build -f zookeeper.Dockerfile -t alex/zookeeper:3.4.6 .
2.3 启动Kafka集群
使用下面命令启动三个Kafka容器,分别是kafka0,kafka1,kafka2,我们看到启动容器时传入了BROKER_ID,BROKER_PORT等变量。这就可以很方便的启动多个容器。
docker run -itd --name kafka0 -h kafka0 -p9092:9092 -e BROKER_ID=0 -e BROKER_PORT=9092 --link zookeeper alex/kafka_cluster:0.8.2.2
docker run -itd --name kafka1 -h kafka1 -p9093:9092 -e BROKER_ID=1 -e BROKER_PORT=9092 --link zookeeper alex/kafka_cluster:0.8.2.2
docker run -itd --name kafka2 -h kafka2 -p9094:9092 -e BROKER_ID=2 -e BROKER_PORT=9092 --link zookeeper alex/kafka_cluster:0.8.2.2
3. 验证是否集群正常
进入kafka0容器内, 创建topic1
docker exec -it kafka0 bash
bin/kafka-topics.sh --zookeeper zookeeper:2181 --topic topic1 --create --replication-factor 2 --partitions 3
bin/kafka-topics.sh --zookeeper zookeeper:2181 --topic topic1 --describe

启动consumer
bin/kafka-console-consumer.sh --zookeeper zookeeper:2181 --topic topic1
进入kafka2容器内, 启动producer
bin/kafka-console-producer.sh --broker-list kafka2:9092 --topic topic1`</pre>

发送一些消息,我看到consumer端正常接收。
这就说明集群配置成功。
4. 验证min.insync.replicas和request.required.acks的作用。
我们创建topic2,并将min.insync.replicas设为2,partitions为1。
bin/kafka-topics.sh --zookeeper zookeeper:2181 --topic topic2 --create --config min.insync.replicas=2 --replication-factor 2 --partitions 1
bin/kafka-topics.sh --zookeeper zookeeper:2181 --topic topic2 --describe

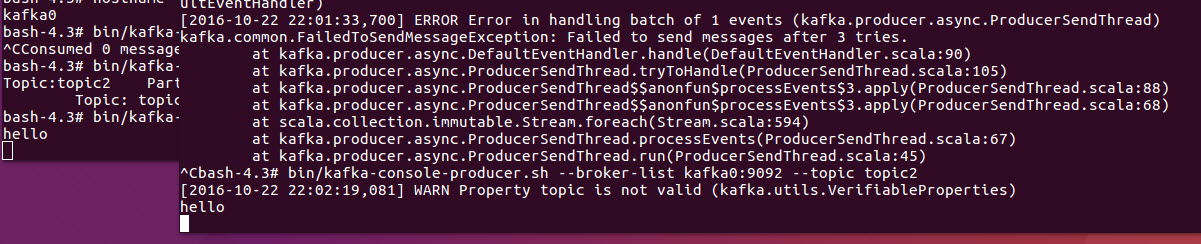
我们看到topic2分配在了kafka2上,并且kafka0是备份,ISR是0和2,现在我们将kafka1和kafka2的broker关闭。我们看到leader已自动转为broker0。然后启动consumer
bin/kafka-console-consumer.sh --zookeeper zookeeper:2181 --topic topic
在另一个终端上启动producer,并将request-required-acks设置为-1
bin/kafka-console-producer.sh --broker-list kafka0:9092 --topic topic2 --request-required-acks -1
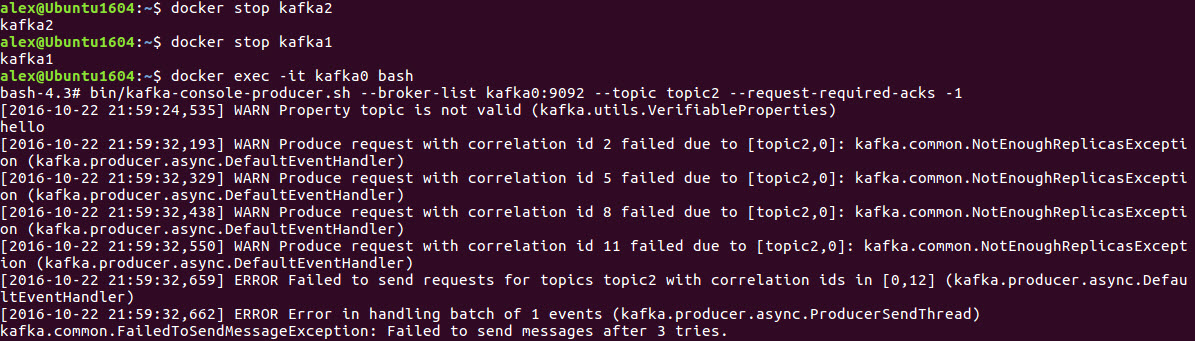
我们看到此时发送消息,kafka出现错误。原因是我们在producer发送时设置了检查replicas是否都收到数据的确认,但是因为我们已经关闭broker2, 所以尝试发送3次未果后,producer返回错误。
显然,我们将producer以默认设置发送消息时,consumer马上收到消息了。