Kafka入门之七:Kafka的offset管理
1. Low Level Consumer(Simple Consumer)的offset管理
上一节我们讲到了kafka的High Level Consumer的消息消费是自动根据offset的顺序消费的。但有时候用户希望比Consumer Group更好的控制数据的消费,比如
- 同一条消息读多次,方便Replay。
- 只消费某个Topic的部分Partition。
- 管理事务,从而确保每条消息被处理一次。
kafka提供了kafka.javaapi.consumer.SimpleConsumer这个API,但是相比High Level Consumer,Low Level Consumer要求用户做大量的额外工作,如
在应用程序中跟踪处理offset,并决定下一条消费哪条消息。
- 获知每个Partition的Leader。
- 处理Leader的变化。
- 处理多Consumer的协作。
下面一段代码,演示了每次从特定Partition的特定offset开始fetch特定大小的消息,如果这些值固定,返回的消息是固定的。
import java.nio.ByteBuffer;
import kafka.api.FetchRequest;
import kafka.api.FetchRequestBuilder;
import kafka.javaapi.FetchResponse;
import kafka.javaapi.consumer.SimpleConsumer;
import kafka.javaapi.message.ByteBufferMessageSet;
import kafka.message.MessageAndOffset;
public class DemoLowLevelConsumer {
public static void main(String[] args) throws Exception {
final String topic = "topic1";
String clientID = "DemoLowLevelConsumer1";
SimpleConsumer simpleConsumer = new SimpleConsumer("kafka0", 9092, 100000, 64 * 1000000, clientID);
FetchRequest req = new FetchRequestBuilder().clientId(clientID)
.addFetch(topic, 0, 0L, 50000).addFetch(topic, 1, 0L, 50000).addFetch(topic, 2, 0L, 50000).build();
FetchResponse fetchResponse = simpleConsumer.fetch(req);
ByteBufferMessageSet messageSet = (ByteBufferMessageSet) fetchResponse.messageSet(topic, 0);
for (MessageAndOffset messageAndOffset : messageSet) {
ByteBuffer payload = messageAndOffset.message().payload();
long offset = messageAndOffset.offset();
byte[] bytes = new byte[payload.limit()];
payload.get(bytes);
System.out.println("Offset:" + offset + ", Payload:" + new String(bytes, "UTF-8"));
}
}
}
2. High Level Consumer的offset管理
对于High Level Consumer来说,offset是自动管理的,我们只需要在参数里设置自动commit还是手工commit。
auto.commit.enable=true
auto.commit.interval.ms=60 * 1000
如果auto.commit.enable=false,那么我们就要在程序中手工指定何时执行下面这条语句。
ConsumerConnector.commitOffsets();
3. Offset的存储
kafka通过参数设置可以指定offset存储的位置,在zookeeper里还是在kafka上。当然要把dual.commit.enabled设置为true。下面的设置表示offset存储在Kafka上。
offsets.storage=kafka
dual.commit.enabled=true
4. Offse的范围查询
kafka提供了一个工具可以查询指定topic的offset范围。如查询topic1的offset最小值和最大值。
最小值
bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list kafka0:9092 -topic topic1 --time -2
最大值
bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list kafka0:9092 -topic topic1 --time -1
当然通过这个工具,我们还可获取指定timestamp的offset,具体用法参见此命令help。
5. 日志压缩
5.1 原理
为什么日志压缩放在这里讲呢?因为kafka的日志压缩跟offset有关,启动压缩机制后,kafka只保留每一Key的最大的offset(也就是最新值),而把旧的值在压缩过程中删除掉。如下图。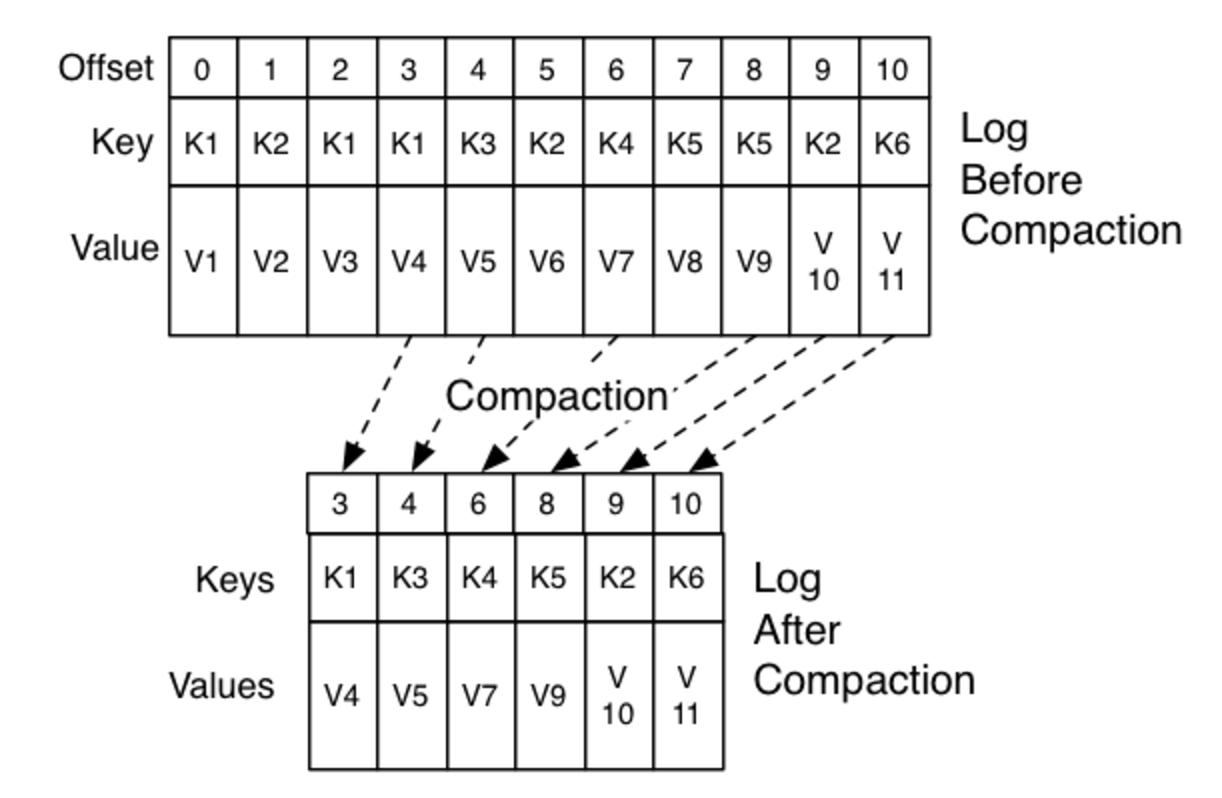
5.2 配置
为实现日志压缩,我们必须修改Kafka配置文件server.properties,把log.cleaner.enable设置为true,然后重启kafka。
5.3 实验演示
5.3.1 目标
创建一个topic,将其log.cleanup.policy设置为compact,等clean(compact)过后使用consumer消费该topic,打印出每条消息的partition key offset,观察其offset是否连续.
5.3.2 步骤
a)创建topic1,注意这个topic里加了两个配置cleanup.policy=compact及segment.bytes=512,这将会对这个topic启动日志压缩,并且分段文件达到512字节就轮转。
bin/kafka-topics.sh --zookeeper zookeeper0:2181/kafka --topic topic1 --create --config cleanup.policy=compact --config segment.bytes=512 --replication-factor 1 --partitions 3
b)发送消息,我们连续10次发送key为0,1,2的消息。(确保超过512字节)
c)消费消息,停止消费,再连续3次发送,再消费消息。看下图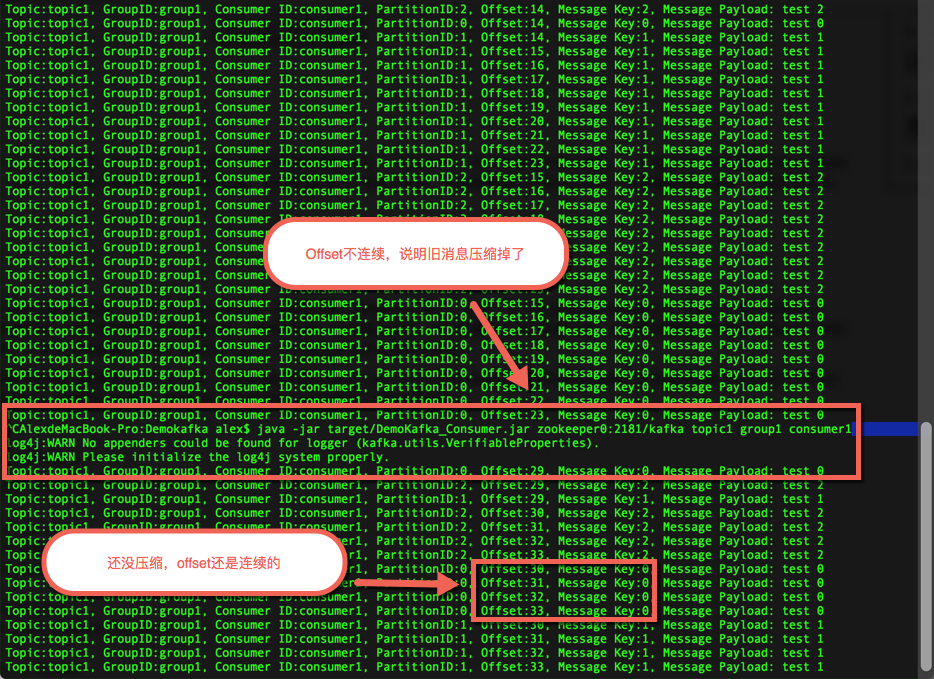
查看kafka上的log目录,看到生成了以第一个offset的不同log,旧的log在删除过程中。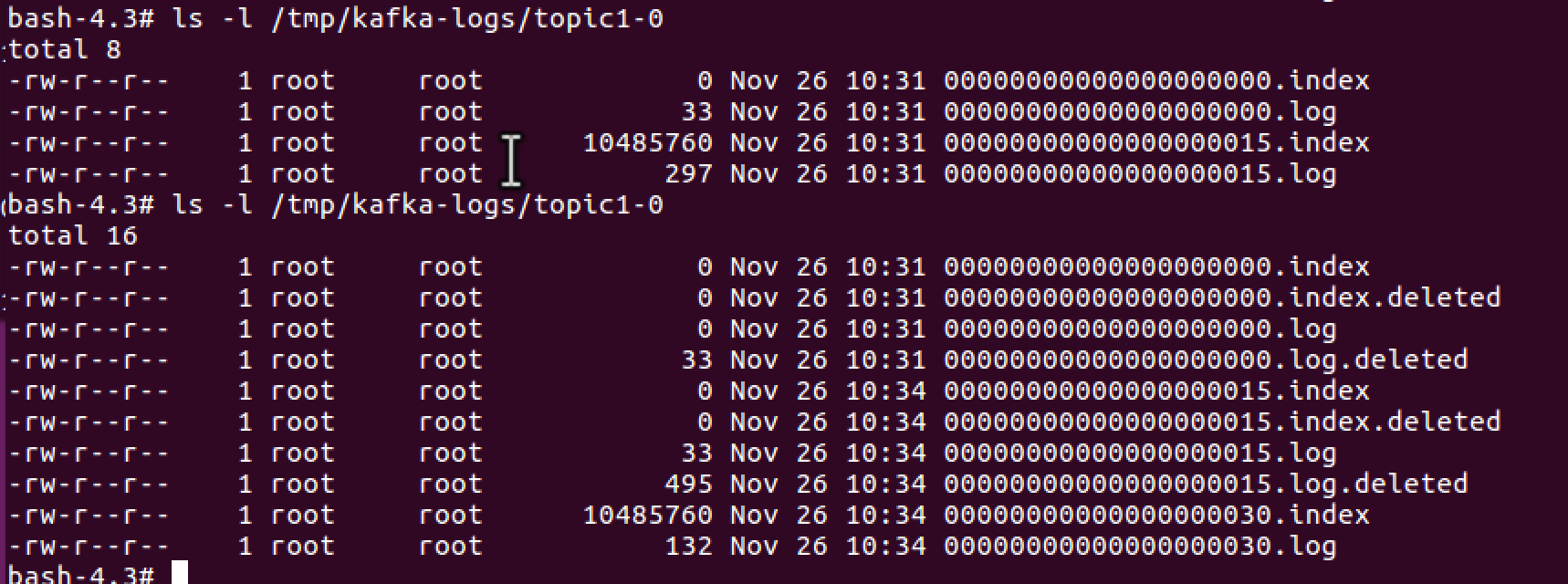
查看log文件的内容,看到压缩过的log只保留了最后一个offset。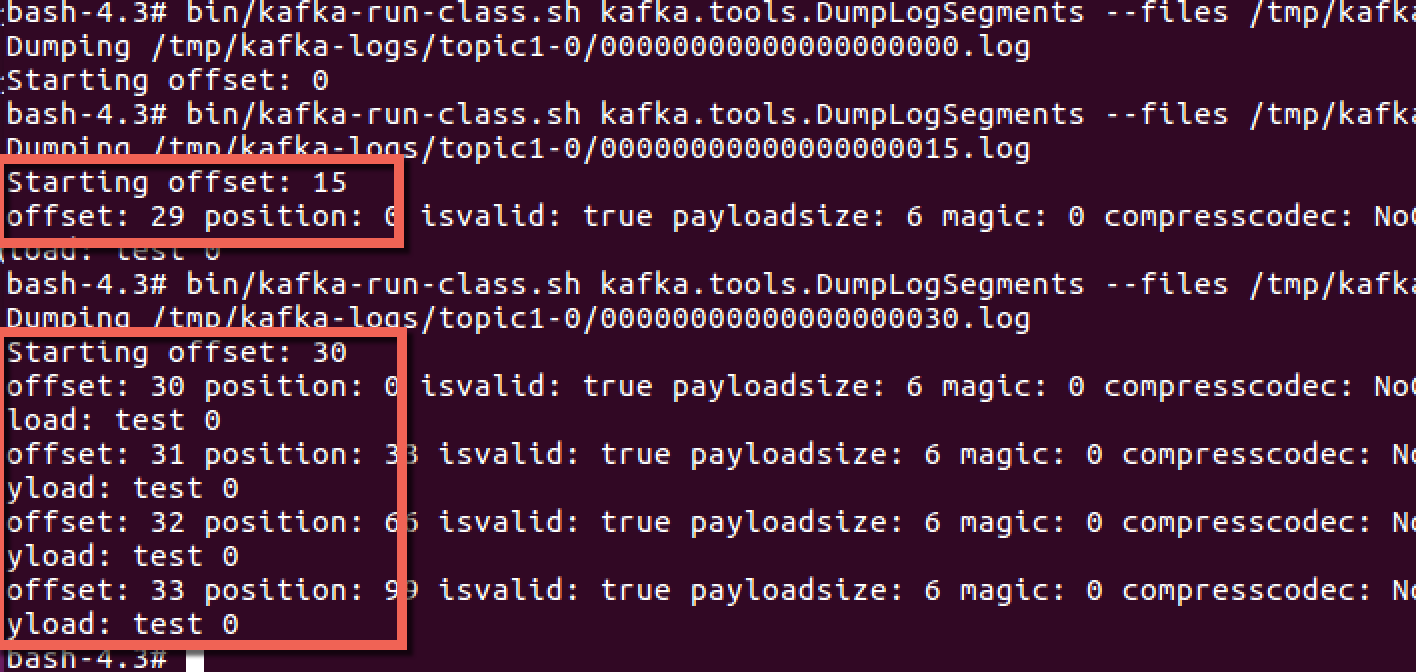
5.3.3 实验小结
- 一直保持消费Log head的consumer可按顺序消费所有消息,并且offset连续。
- 任何从offset 0开始的读操作至少可读到每个key对应的最后一条消息。
- 每条消息的offset保持不变,offset是消息的永久标志符。
- 消费本身的顺序不会被改变。