Storm的基本概念和组件
1. Storm是什么
Storm是开源的、分布式、流式计算系统。 我们知道Hadoop是开源的、分布式 系统,但是,Hadoop它只能处理适合进行批量计算的需求,对于,非批量的计算就不能够满足要求了。于是类似Storm流式计算系统就雨后春笋般的冒出来了,如Yahoo的S4,IBM的StreamBase,Amazon的Kinesis,Spark的Streaming,Google的Millwheel,不消说,Storm是业内最知名的。
2. Storm的主要特点
Storm的主工程师Nathan Marz表示: Storm可以方便地在一个计算机集群中编写与扩展复杂的实时计算,Storm之于实时处理,就好比Hadoop之于批处理。Storm保证每个消息都会得到处理,而且它很快——在一个小集群中,每秒可以处理数以百万计的消息。更棒的是你可以使用任意编程语言来做开发。
Storm的主要特点如下:
- 简单的编程模型。类似于MapReduce降低了并行批处理复杂性,Storm降低了进行实时处理的复杂性。
- 可以使用各种编程语言。你可以在Storm之上使用各种编程语言。默认支持Clojure、Java、Ruby和Python。要增加对其他语言的支持,只需实现一个简单的Storm通信协议即可。
- 容错性。Storm会管理工作进程和节点的故障。
- 水平扩展。计算是在多个线程、进程和服务器之间并行进行的。
- 可靠的消息处理。Storm保证每个消息至少能得到一次完整处理。任务失败时,它会负责从消息源重试消息。
- 快速。系统的设计保证了消息能得到快速的处理,使用ØMQ作为其底层消息队列。
- 本地模式。Storm有一个“本地模式”,可以在处理过程中完全模拟Storm集群。这让你可以快速进行开发和单元测试。
不过Storm不是一个完整的解决方案。使用Storm时你需要关注以下几点:
如果使用的是自己的消息队列,需要加入消息队列做数据的来源和产出的代码
需要考虑如何做故障处理:如何记录消息队列处理的进度,应对Storm重启,挂掉的场景
需要考虑如何做消息的回退:如果某些消息处理一直失败怎么办?
3. Storm组件及概念
1. Nimbus:雨云,主节点的守护进程,负责为工作节点分发任务(任务写入Zookeeper)。
2. Supervisor:从Zookeeper接收Nimbus分配的任务,启动和停止属于自己管理的worker进程。
3. Worker:运行具体处理组件逻辑的进程。
4. Topology:一个Storm拓扑打包了一个实时处理程序的逻辑。一个Storm拓扑类似一个Hadoop的MapReduce任务(Job)。主要区别是MapReduce任务最终会结束,而拓扑会一直运行(当然直到你杀死它)。一个拓扑是一个通过流分组(stream grouping)把Spout和Bolt连接到一起的拓扑结构。图的每条边代表一个Bolt订阅了其他Spout或者Bolt的输出流。一个拓扑就是一个复杂的多阶段的流计算。
5. Spout:龙卷,是一个在Topology中产生源数据流的组件。通常情况下Spout会从外部数据源中读取数据,然后转换为Topology内部的源数据。Spout 是一个主动的角色,其接口中有个nextTuple()函数, Storm框架会不停地调用此函数,用户只要在其中生成源数据即可。
6. Bolt:雷电,是一个在Topology中接受数据然后执行处理的组件。Bolt可以执行过滤、函数操作、合并、写数据库等任何操作。Bolt是一个被动的角色,其接口中有个execute(Tuple input)函数,在接受到消息后会调用此函数,用户可以在其中执行自己想要的操作。
7. Task:Worker中每一个Spout/Bolt的线程称为一个Task. 在 Storm 0.8之后,task不再与物理线程对应,同一个Spout/Bolt的Task可能会共享一个物理线程,该线程称为Executor。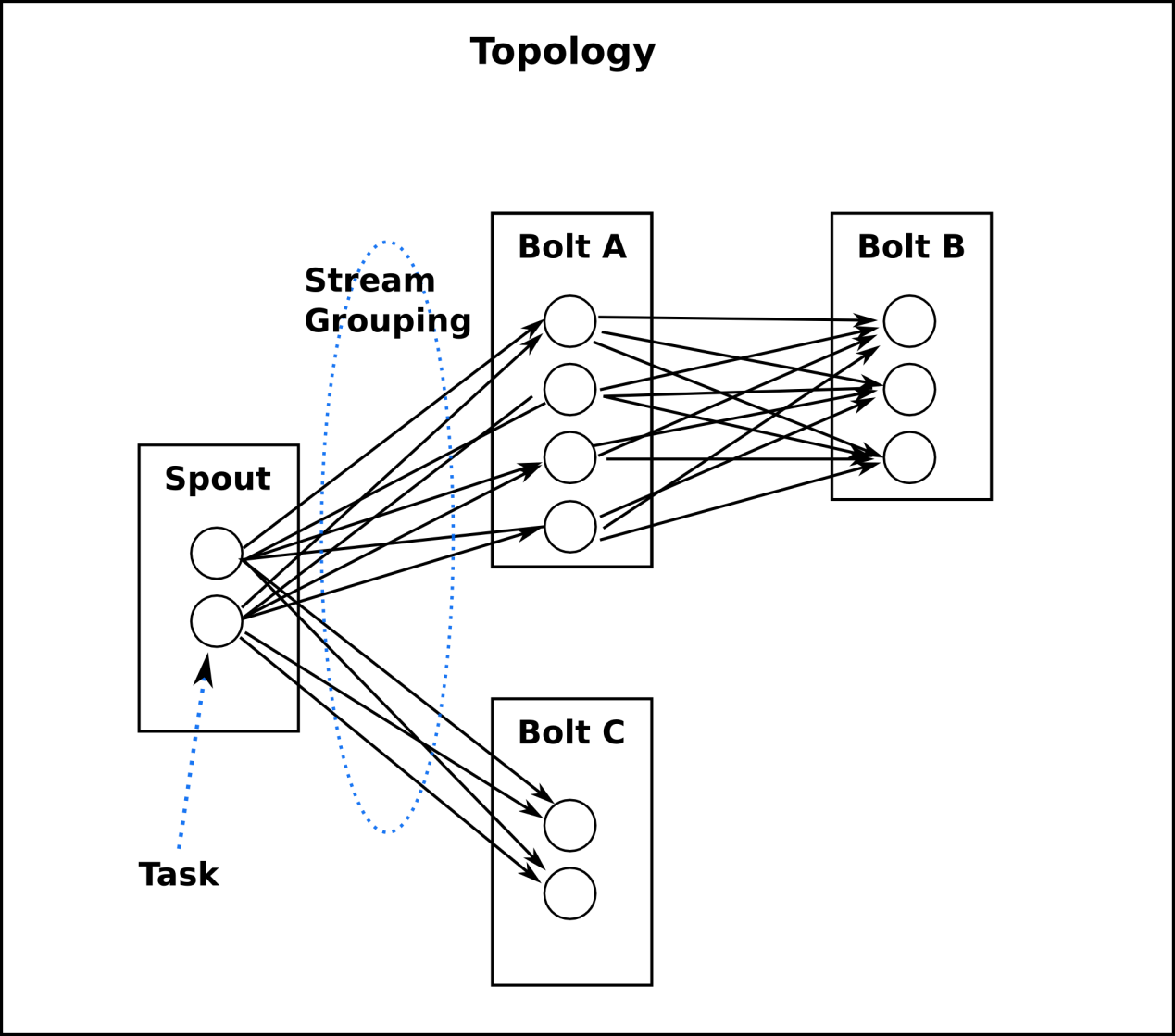
8. Tuple:元组,一次消息传递的基本单元。
9. Stream:源源不断传递的Tuple就组成了stream。
10.Stream Grouping:即消息的partition方法。流分组策略告诉Topology如何在两个组件之间发送Tuple。 Storm 中提供若干种实用的grouping方式,包括shuffle, fields hash, all, global, none, direct和localOrShuffle等。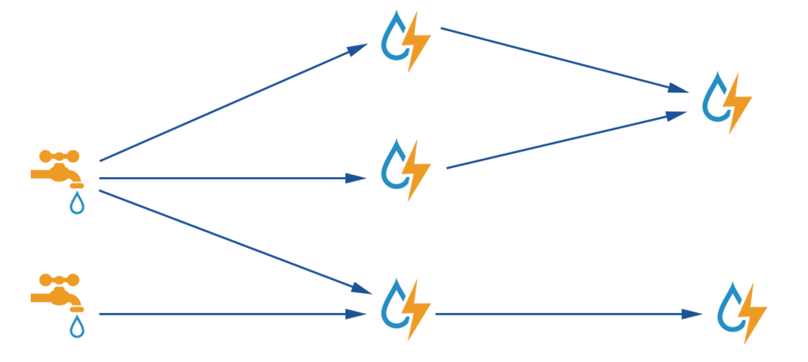
4. Storm基本架构
Nimbus和Supervisor之间的通信依靠Zookeeper来完成,并且Nimbus进程和Supervisor都是快速失败和无状态的。所有的状态要么在Zookeeper里面,要么在本地磁盘上。这就意味着你可以用Kill -9 来杀死 Nimbus和Supervisor进程,然后在重启它们,它们可以继续工作,就像什么也没发生。这个设计使Storm具有非常高的稳定性。
5. 与Hadoop的区别
Hadoop使用磁盘作为中间交换的介质,而Storm的数据是一直在内存中流转的。两者面向的领域也不完全相同,一个是批量处理,基于任务调度的;另外一个是实时处理,基于流。以水为例,Hadoop可以看作是纯净水,一桶桶地搬;而Storm是用水管,预先接好(Topology),然后打开水龙头,水就源源不断地流出来了。
6. 与Spark Streaming的区别
虽然这两个框架都提供可扩展性和容错性,它们根本的区别在于他们的处理模型。Storm处理的是每次传入的一个事件,而Spark Streaming是处理某个时间段窗口内的事件流。因此,Storm处理一个事件可以达到秒内的延迟,而Spark Streaming则有几秒钟的延迟。