Docker proxy关停测试
1. 简介
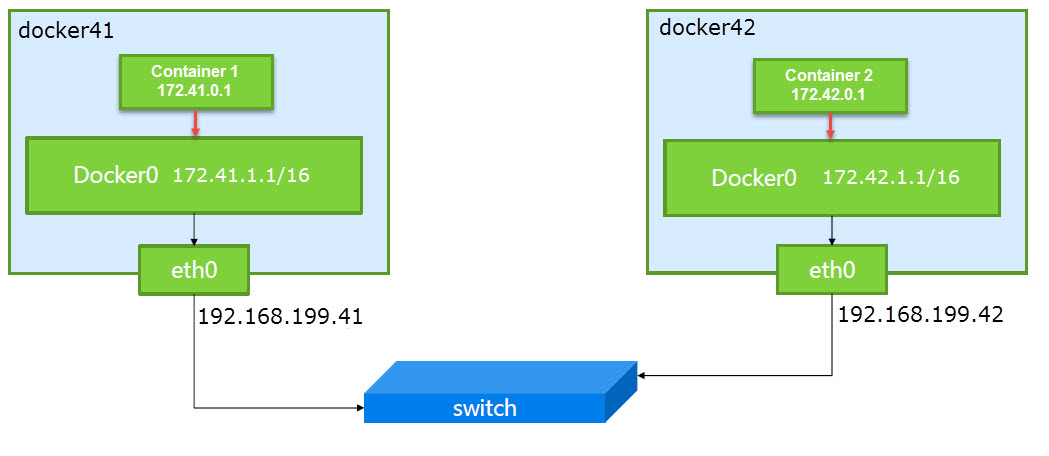
正常情况下,当启动一个端口映射的容器时,docker –proxy进程就会起来,实现宿主机上0.0.0.0地址上对容器的访问代理,在docker-proxy加入Docker之后相当长的一段时间内。Docker爱好者普遍感受到,很多场景下,docker-proxy并非必需,甚至会带来一些其他的弊端。
影响较大的场景主要有两种。
第一,单个容器需要和宿主机有多个端口的映射。此场景下,若容器需要映射1000个端口甚至更多,那么宿主机上就会创建1000个甚至更多的 docker-proxy进程。据不完全测试,每一个docker-proxy占用的内存是4-10MB不等。如此一来,直接消耗至少4-10GB内存, 以及至少1000个进程,无论是从系统内存,还是从系统CPU资源来分析,这都会是很大的负担。
第二,众多容器同时存在于宿主机的情况,单个容器映射端口极少。这种场景下,关于宿主机资源的消耗并没有如第一种场景下那样暴力,而且一种较为慢性的方式侵噬资源。
如今,Docker Daemon引入--userland-proxy这个flag,将以上场景的控制权完全交给了用户,由用户决定是否开启,也为用户的场景的proxy代理提供了灵活性。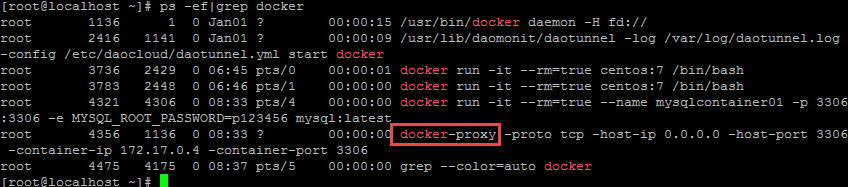
那么我们怎么通过--userland-proxy这个flag来设置呢?不同版本位置稍有不同。
Docker Volume定义及实例应用
Docker构建镜像实例
postgresql使用UUID功能
1. UUID介绍
1.1 什么是UUID?
UUID是Universally Unique Identifier的缩写,它是在一定的范围内(从特定的名字空间到全球)唯一的机器生成的标识符。UUID具有以下涵义:
1.1.1 经由一定的算法机器生成
为了保证UUID的唯一性,规范定义了包括网卡MAC地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素,以及从这些元素生成UUID的算法。UUID的复杂特性在保证了其唯一性的同时,意味着只能由计算机生成。
1.1.2 非人工指定,非人工识别
UUID是不能人工指定的,除非你冒着UUID重复的风险。UUID的复杂性决定了“一般人“不能直接从一个UUID知道哪个对象和它关联。
1.1.3 在特定的范围内重复的可能性极小
UUID的生成规范定义的算法主要目的就是要保证其唯一性。但这个唯一性是有限的,只在特定的范围内才能得到保证,这和UUID的类型有关,UUID是16字节128位长的数字,通常以36字节的字符串表示,示例如下:3F2504E0-4F89-11D3-9A0C-0305E82C3301其中的字母是16进制表示,大小写无关。GUID(Globally Unique Identifier)是UUID的别名;但在实际应用中,GUID通常是指微软实现的UUID。
Postgres-XL集群安装与配置
1.Postgres-XL简介
Postgres-XL是从Postgres-XC衍生而来的一款产品, 经过改良, 对MPP这块做了比较大的改进.所以它同样包含了以下组件。
gtm:利用pg的MVCC全局地控制tuple,一个pgxc中只能有一个gtm。
gtm_standby:gtm的备机。
gtm_proxy:降低gtm压力,用多个代理来进行对coordinator进行操作。
coordinator:协调节点,负责操作所有datanode,本身不存放数据。在coordinator上可以以distribute切片(分布)或者replication复制的方式进行创建表。
datanode:存放数据的节点,如果数据在coordinator上是以切片方式建的表则数据只存放此表的一部分数据,如果是replication方式的表则存放全部数据。
我们来看一下Postgres-XL和postgresql, Postgres-XC的对比 :
Postgres-XC集群安装与配置
1.Postgres-XC简介
PostgreSQL-XC 是一种提供写可靠性,多主节点数据同步,数据传输的开源集群方案,它包括很多组件,这些 PostgreSQL-XC 组件可以分别安装在多台物理机器或者虚拟机上。
组件:
gtm:利用pg的MVCC全局地控制tuple,一个pgxc中只能有一个gtm。
gtm_standby:gtm的备机。
gtm_proxy:降低gtm压力,用多个代理来进行对coordinator进行操作。
coordinator:协调节点,负责操作所有datanode,本身不存放数据。在coordinator上可以以distribute切片(分布)或者replication复制的方式进行创建表。
datanode:存放数据的节点,如果数据在coordinator上是以切片方式建的表则数据只存放此表的一部分数据,如果是replication方式的表则存放全部数据。
我们来看一下Postgres-XL和postgresql, Postgres-XC的对比 :

使用Keepalived实现将lvs进行高可用
Storm on Yarn平台搭建
1. 简介
1)Storm:一个实时计算框架,与Hadoop离线计算框架互补,分别用于解决不同场景下的问题。Storm的官方网站是 http://storm.apache.org,关于Storm,可以参见淘宝搜索的文章:[Storm简介](http://www.searchtb.com/2012/09/introduction-to-storm.html)。
2)YARN:YARN是Hadoop 2.0中新引入的资源管理系统,所有应用程序和框架,比如MapReduce、Storm和Spark等,均可运行在YARN之上。
3)Storm On YARN:尝试将Storm运行在YARN上,这将带来众多好处。Storm On YARN最有名是Yahoo!的开源实现。