Hadoop 1.2.1 完全分布式安装部署
1.准备工作
1.1 安装前,准备三台CENTOS 6.6系统的主机或虚机,并且关闭防火墙及selinux。
1.2 按如下表格配置IP地址,修改hosts文件及本机名。
| IP | 主机名 | 节点 |
|---|---|---|
| 192.168.199.11 | hadoop11 | Master |
| 192.168.199.12 | hadoop12 | Slave1 |
| 192.168.199.13 | hadoop13 | Slave2 |
1.3 修改master节点hosts文件。

1.4 修改master节点本机名。

1.5 修改master节点IP地址。
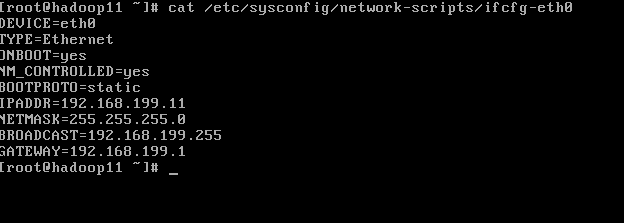
同样方法修改Slave1,Slave2的IP地址,hosts文件及本机名。
2.安装ORACLE JDK
先卸载本机openJDK,使用rpm -qa|grep java查看,然后用rpm -e 卸载
从oracle网站找到最新JDK,我这选择了JDK8,可以从以下地址下载。
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
下载好以后解压,并移至/usr/java,如果没有可以mkdir命令建立。
1 | #tar -xzvf jdk-8u51-linux-x64.gz |
3.安装配置
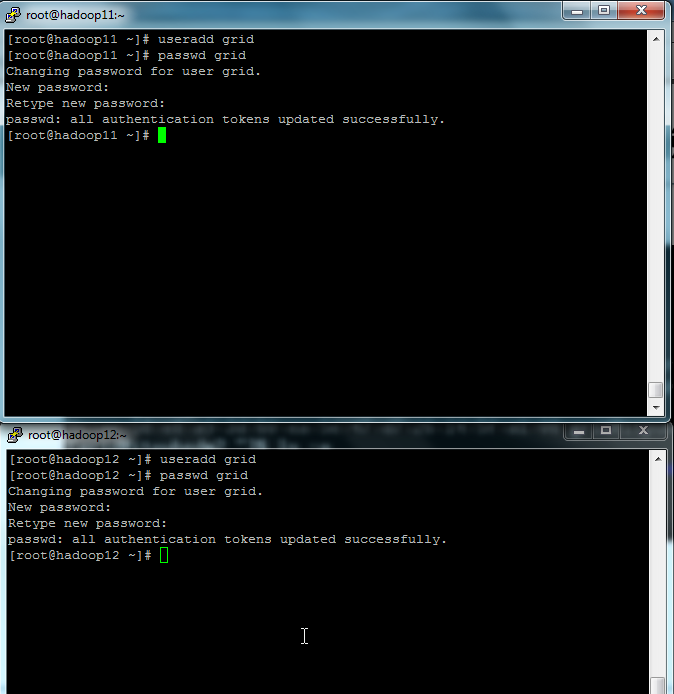
3.1 设置账号
在各节点分别建立Hadoop运行帐号grid,并设置密码。
3.2 配置SSH各节点免密码登陆。
在各节点分别以grid用户名生成两个密钥文件,一个是私钥id_rsa,另一个是公钥id_rsa.pub。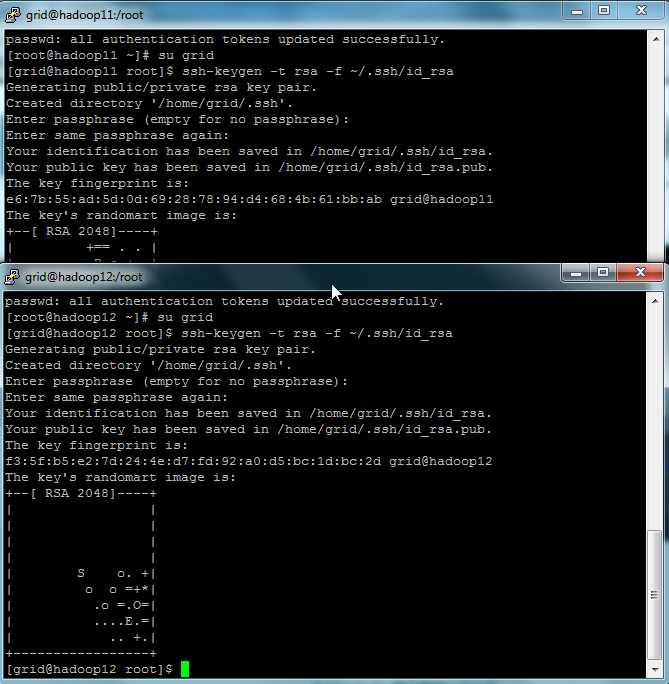
在master机上把三个节点的公钥都添加至文件authorized_keys,然后分发至各节点。
在hadoop11节点上,如下命令。
#cp /home/grid/.ssh/id_rsa.pub /home/grid/.ssh/authorized_keys
#scp hadoop12:/home/grid/.ssh/id_rsa.pub pubkeys12
#scp hadoop13:/home/grid/.ssh/id_rsa.pub pubkeys13
#cat pubkeys12 >> /home/grid/.ssh/authorized_keys
#cat pubkeys13 >> /home/grid/.ssh/authorized_keys
#rm pubkeys12
#rm pubkeys13
最后分发authorized_keys文件到其它节点。
#scp /home/grid/.ssh/authorized_keys hadoop12:/home/grid/.ssh
#scp /home/grid/.ssh/authorized_keys hadoop13:/home/grid/.ssh
3.3 下载hadoop1.2.1
在Master机下载并解压Hadoop1.2.1(使用grid用户名),找到最近的hadoop镜像,使用wget下载1.2.1版本。
#wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
解压hadoop-1.2.1.tar.gz文件
#tar -xzvf hadoop-1.2.1.tar.gz
#cd hadoop-1.2.1
#mkdir tmp
3.4 修改配置文件
#cd hadoop-1.2.1
#cd conf
修改hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_51
修改core-site.xml
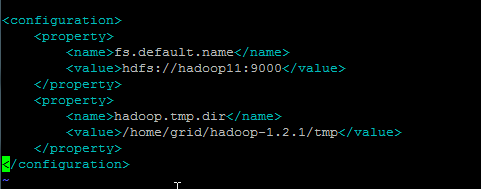
修改hdfs-site.xml
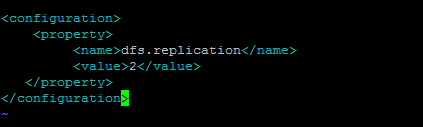
修改mapred-site.xml
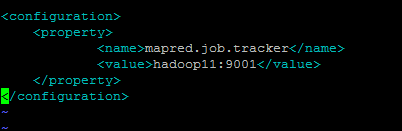
修改masters,slaves
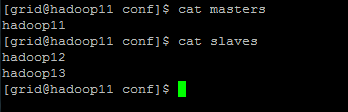
3.5 配置文件分发
将配置文件分发至各Salve节点。
#scp -r /home/grid/hadoop-1.2.1 hadoop12:/home/grid
#scp -r /home/grid/hadoop-1.2.1 hadoop13:/home/grid
3.6 格式化
将Master机格式化namenode。
#bin/hadoop namenode -format
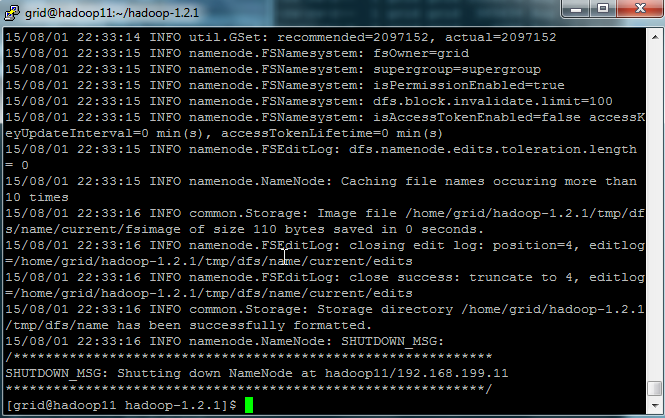
至此,安装配置工作基本完成。
4.启动
使用start-all.sh启动hadoop。
#bin/start-all.sh
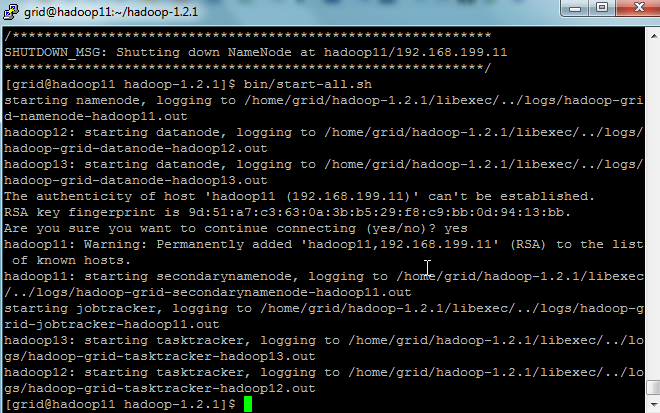
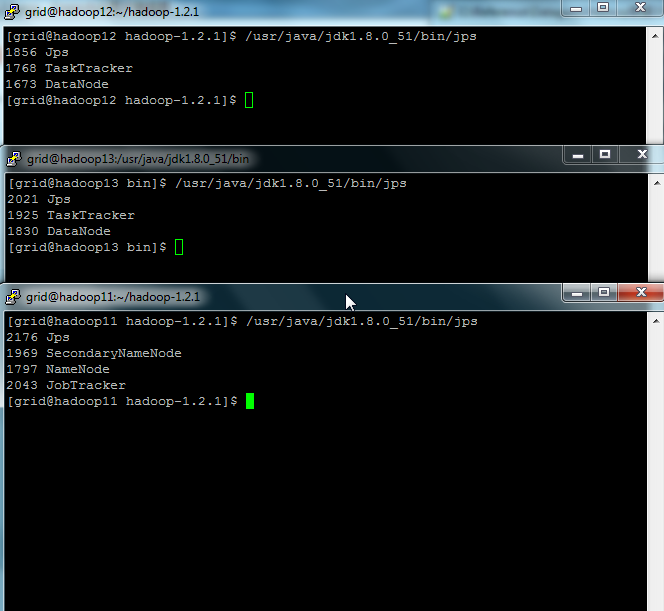
5.验证
Master机应该启动NameNode,SecondaryNameNode,JobTracker;
Slave机应该启动DataNode,TaskTracker。