基于Mycat的Oracle数据迁移至Mysql方案
1. 简介
我们知道由于各种各样的原因,一些数据库比如oracle不得不迁移至其他数据库而又不能中断业务时,下面的这些问题常常困扰着技术人员,哪些表和库要迁移,哪些暂时不能动,迁移后数据如何同步,一般靠谱的方案是从影响最小的模块和数据表开始改造,逐步上线。那么何种解决方案可以实现这样的改造?本文我们就基于mycat来实现下面的一个场景,用户表与订单表的数据迁移到MySQL,转账记录表则还保留在oracle。
改造前结构是这样的: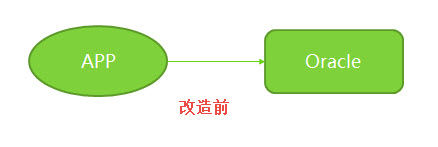
改造后: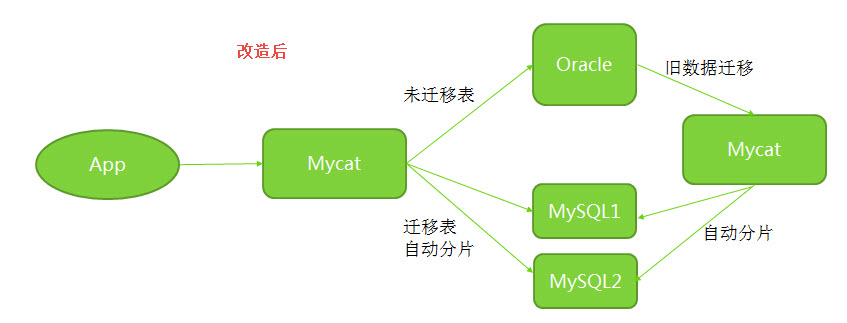
2. 准备工作
在具体测试前,我们先做一些准备工作。
2.1 Orale安装
准备oracle数据库,这里我们用docker实现,简单起见,我们直接从网上下载oracle的express版本。
docker create --name oraclexe11g01 -p 8080:8080 -p 1521:1521 martinsthiago/oraclexe-11g-fig
docker start oraclexe11g01
注意如果要使用GBK字符集,需要在客户端,服务器端做一些设置。
客户端
export NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
服务器端
ALTER DATABASE CHARACTER SET ZHS16GBK;
2.2 创建表
创建用户表,订单表,转账记录表
create table Z_USER
(
userid INTEGER
, uname VARCHAR2(50)
);
CREATE TABLE Z_ORDERS
(
USERID INTEGER
, productId INTEGER
, unitprice NUMBER(12, 5)
, qty INTEGER
, orderDate DATE
, orderLineNr INTEGER
, orderNr INTEGER
)
;
create table Z_PAY
(
payid INTEGER
, orderNr INTEGER
, paydate DATE
, payamt NUMBER(15,2)
, userid INTEGER
);
2.3 生成测试数据
这里我们通过ETL工具kettle来生成用户表,订单表,转账记录表的测试数据,具体过程略,以下就展示结果。
用户表生成10万条记录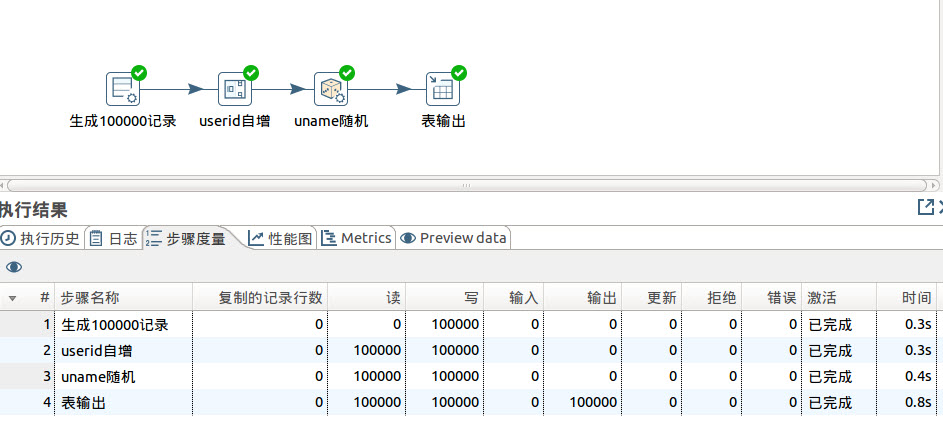
订单表生成1万条记录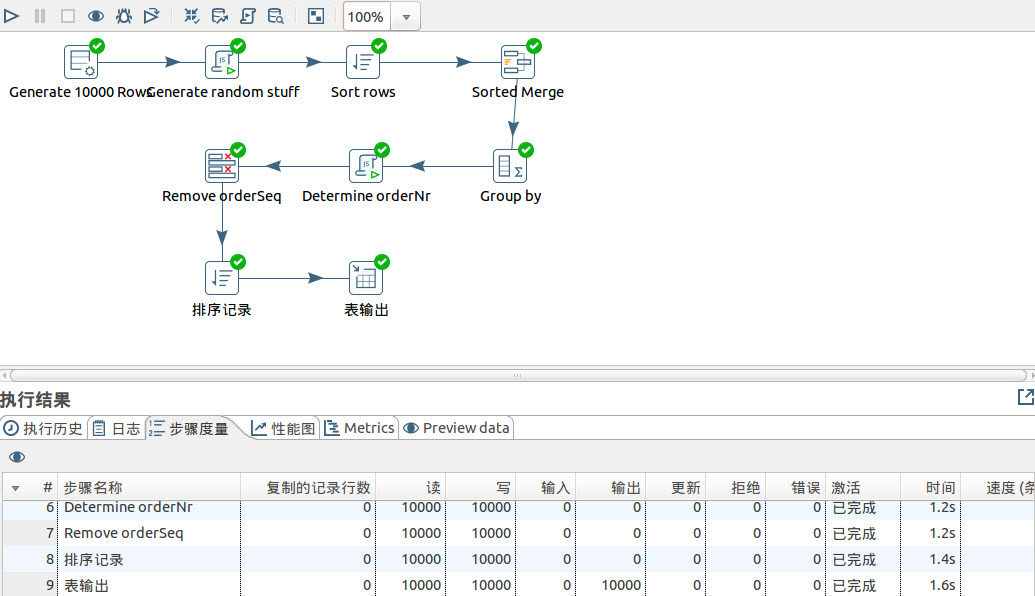
转账记录表生成9914条记录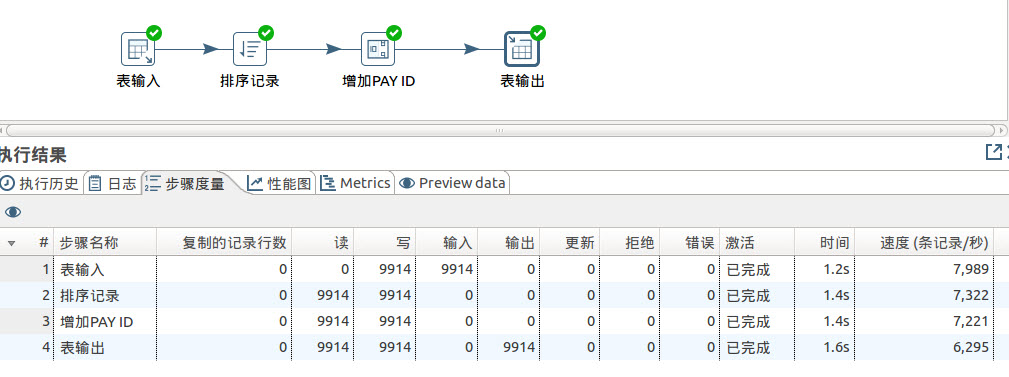
3. Mycat配置
在假设的场景中,一共有10万用户数,所以我们根据用户ID进行分片,1到5万在第一个分片数据库,5万零1到10万在第二个分片数据库。
3.1 配置schema.xml
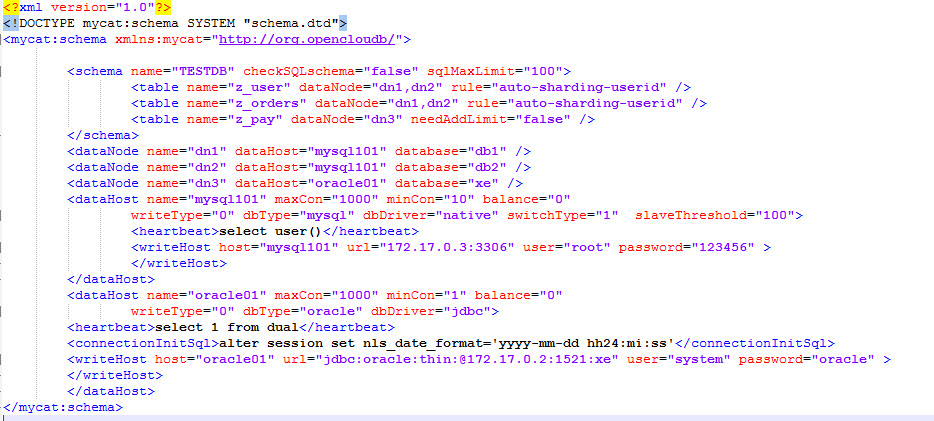
3.2 配置rule.xml
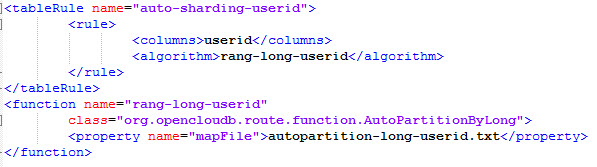
3.3 配置autopartition-long-userid.txt
[root@localhost ~]# vi autopartition-long-userid.txt
# range start-end ,data node index
# K=1000,M=10000.
0-50000=0
50001-100000=1
配置完成,启动mysql数据库容器,mycat容器。
4. 转移测试
4.1 转账记录表
根据设置,转账记录表还保留在oracle数据库,我们看看通过mycat数据是否可以查询及新增数据。在mycat 8066端,我们看到新增数据顺利插入至到dn3,也就是我们定义的oracle数据库。
mysql> insert into Z_PAY( payid,orderNr, paydate,payamt,userid ) values (9915,5000686,'2016-01-31',10.2 ,7029);
Query OK, 1 row affected (0.01 sec)
OK!
mysql> explain insert into Z_PAY( payid,orderNr, paydate,payamt,userid ) values (9915,5000686,'2016-01-31',10.2 ,7029);
+-----------+---------------------------------------------------------------------------------------------------------+
| DATA_NODE | SQL |
+-----------+---------------------------------------------------------------------------------------------------------+
| dn3 | insert into Z_PAY( payid,orderNr, paydate,payamt,userid ) values (9915,5000686,'2016-01-31',10.2 ,7029) |
+-----------+---------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)
mysql>
在oracle sqlplus端,我们可以查询到刚才新增的一条数据。
SQL> select * from z_pay where payid>=9910;
PAYID ORDERNR PAYDATE PAYAMT USERID
---------- ---------- ------------ ---------- ----------
9910 5005517 27-JAN-07 11.78 55819
9911 5008604 28-JAN-07 29.24 87168
9912 5003118 29-JAN-07 37.24 31233
9913 5004690 30-JAN-07 3.58 47576
9914 5000686 31-JAN-07 6.2 7029
9915 5000686 31-JAN-16 10.2 7029
6 rows selected.
SQL>
4.2 用户表
用户表的转移,我们这里也通过ETL工具kettle来实现,需要说明的是kettle可以自动在mysql创建数据库表,下面是结果展示。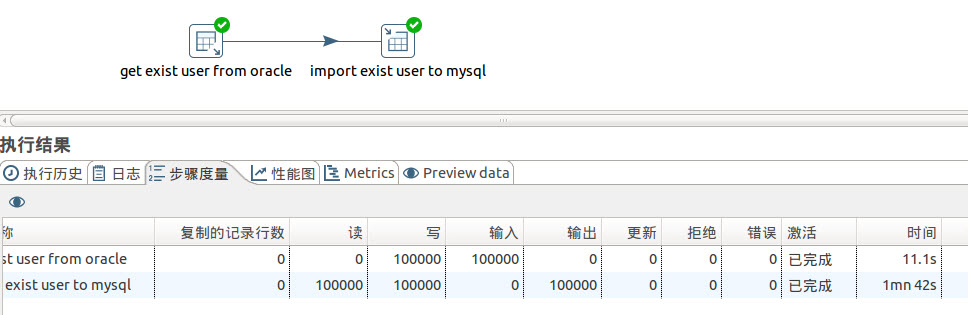
这里要注意的是,连接的mysql实际上是连接的是mycat的8066端口。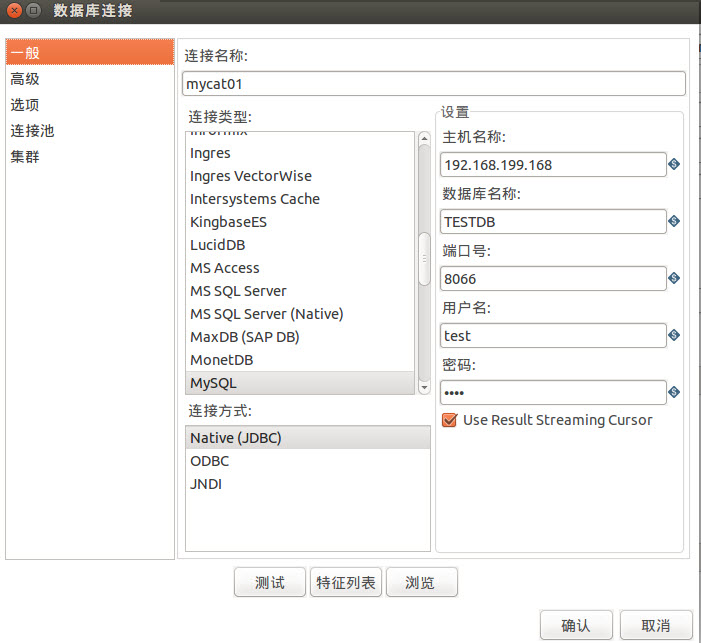
这样在转移的过程中,mycat就已经帮我们进行了数据分片。转移完成后,在mycat8066端,我们看到用户数据分别在dn1,dn2
mysql> explain select count(*) from z_user;
+-----------+-------------------------------------------------+
| DATA_NODE | SQL |
+-----------+-------------------------------------------------+
| dn1 | SELECT COUNT(*) AS COUNT0 FROM z_user LIMIT 100 |
| dn2 | SELECT COUNT(*) AS COUNT0 FROM z_user LIMIT 100 |
+-----------+-------------------------------------------------+
2 rows in set (0.00 sec)
mysql> select count(*) from z_user;
+--------+
| COUNT0 |
+--------+
| 100000 |
+--------+
1 row in set (0.03 sec)
进入mysql的3306,我们看到,用户数据确实根据我们预先定义的分别进入了两个数据库。
mysql> select count(*),min(userid),max(userid) from db1.z_user;
+----------+-------------+-------------+
| count(*) | min(userid) | max(userid) |
+----------+-------------+-------------+
| 50000 | 1 | 50000 |
+----------+-------------+-------------+
1 row in set (0.05 sec)
mysql> select count(*),min(userid),max(userid) from db2.z_user;
+----------+-------------+-------------+
| count(*) | min(userid) | max(userid) |
+----------+-------------+-------------+
| 50000 | 50001 | 100000 |
+----------+-------------+-------------+
1 row in set (0.04 sec)
mysql>
4.3 订单表
同样订单表的转移,我们这里也通过ETL工具kettle来实现,下面是结果展示。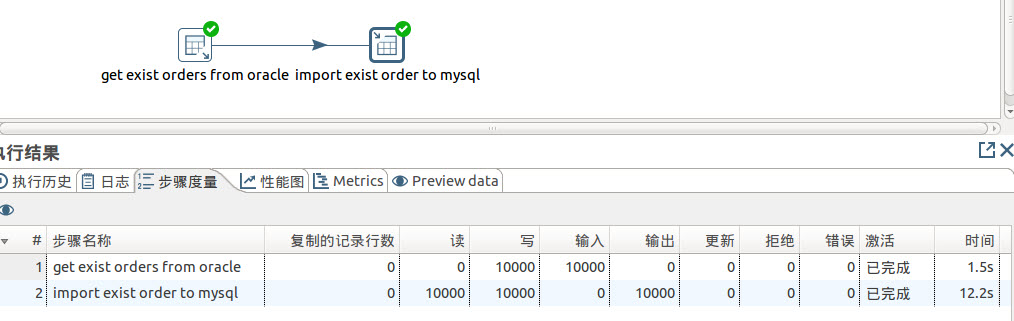
mysql> select count(*) from z_orders;
+--------+
| COUNT0 |
+--------+
| 10000 |
+--------+
1 row in set (0.01 sec)
mysql> explain select count(*) from z_orders;
+-----------+---------------------------------------------------+
| DATA_NODE | SQL |
+-----------+---------------------------------------------------+
| dn1 | SELECT COUNT(*) AS COUNT0 FROM z_orders LIMIT 100 |
| dn2 | SELECT COUNT(*) AS COUNT0 FROM z_orders LIMIT 100 |
+-----------+---------------------------------------------------+
2 rows in set (0.00 sec)
进入mysql的3306,我们看到,订单数据确实根据我们预先定义的分别进入了两个数据库。
mysql> select count(*),min(userid),max(userid) from db1.z_orders;
+----------+-------------+-------------+
| count(*) | min(userid) | max(userid) |
+----------+-------------+-------------+
| 4968 | 3 | 49997 |
+----------+-------------+-------------+
1 row in set (0.01 sec)
mysql> select count(*),min(userid),max(userid) from db2.z_orders;
+----------+-------------+-------------+
| count(*) | min(userid) | max(userid) |
+----------+-------------+-------------+
| 5032 | 50027 | 99989 |
+----------+-------------+-------------+
1 row in set (0.01 sec)
小结,通过以上实验,我们看到通过mycat这个中间件的穿针引线,我们就有可能在完全不中断业务的情况下,顺利的进行数据的迁移及分片工作,当然在实际情况下,场景比以上演示的复杂的多。我们还是可以通过逐步改造,逐步上线的方式完成整个数据的迁移工作。
PS,
1.mycat连接oracle需要复制ojdbc14.jar到mycat的lib目录,
2.kettle连接oracle需要复制ojdbc14.jar到kettle的data-integration/lib目录,
3.kettle连接mysql同样需要复制mysql-connector-java-5.1.38-bin.jar到kettle的data-integration/lib目录。