Kettle数据同步初探
1. 简介
Kettle是一款国外开源的ETL工具,数据抽取高效稳定。其中的数据同步方法可根据需求不同以采取以下方案。
- 触发器:在数据库建立增删改的触发器。触发器将变更放到一张临时表里。
优点:实时同步
缺点:影响到业务系统,因为需要在业务系统建立触发器 - 日志:通过分析源数据库日志,来获得源数据库中的变化的数据。
优点:不影响业务系统
缺点:有一定得延时,对于没有提供日志分析接口的数据源,开发的难度比较大 - 时间戳:在要同步的源表里有时间戳字段,每当数据发生变化,时间戳会记录发生变化的时间
优点:基本不影响业务系统
缺点:要求源表必须有时间戳这一列 - 数据比较:通过比较两边数据源数据,来完成数据同步。一般用于实时性要求不高的场景。
优点:基本不影响业务系统
缺点:效率低 - 全表拷贝:定时清空目的数据源,将源数据源的数据全盘拷贝到目的数据源。一般用于数据量不大,实时性要求不高的场景。
优点:基本不影响业务系统,开发、部署都很简单
缺点:效率低
现在我们就数据比较法来演示kettle数据同步性能调优过程。
环境:虚拟机UBUNTU 15.10,内存4GB,数据库POSTGRES。
2. 准备工作
2.1 安装postgres数据库
我们以Docker容器方式安装postgres数据库
下载postgres 9.5.0 的镜像
docker pull postgres:9.5.0
创建容器mypostgres01,作为主数据库
docker create --name mypostgres01 -p 5432:5432 -e POSTGRES_PASSWORD=123456 postgres:9.5.0
创建容器mypostgres02,作为备数据库
docker create --name mypostgres02 -p 5433:5432 -e POSTGRES_PASSWORD=123456 postgres:9.5.0
分别启动容器
docker start mypostgres01
docker start mypostgres02
alex@ubuntu:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
62a6761dcbb8 postgres:9.5.0 "/docker-entrypoint.s" 15 seconds ago Up 10 seconds 0.0.0.0:5433->5432/tcp mypostgres02
762bf5d078f0 postgres:9.5.0 "/docker-entrypoint.s" 20 seconds ago Up 15 seconds 0.0.0.0:5432->5432/tcp mypostgres01
2.2 创建测试数据库
使用pgAdmin3 分别建立数据库kettle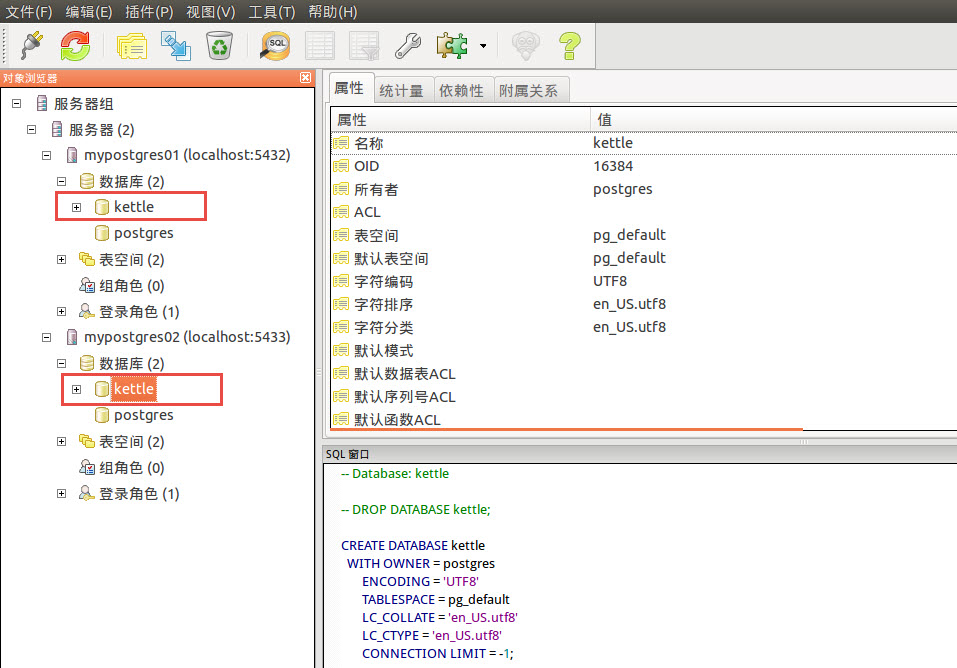
2.3 生成示例数据
我们使用kettle的转换文件在两个数据库分别生成100万条orders数据。orders数据表结构如下。
CREATE TABLE public.orders
(
customerid integer,
productid integer,
discountpct smallint,
nrproducts smallint,
orderdate timestamp without time zone,
orderlinenr bigint,
ordernr integer,
serial integer NOT NULL DEFAULT nextval('orders_serial_seq'::regclass),
CONSTRAINT orders_pkey PRIMARY KEY (serial)
)
具体方法可参见kettle自带的sample转换,转换文件路径如下\samples\transformations\data-generator\generate order data.ktr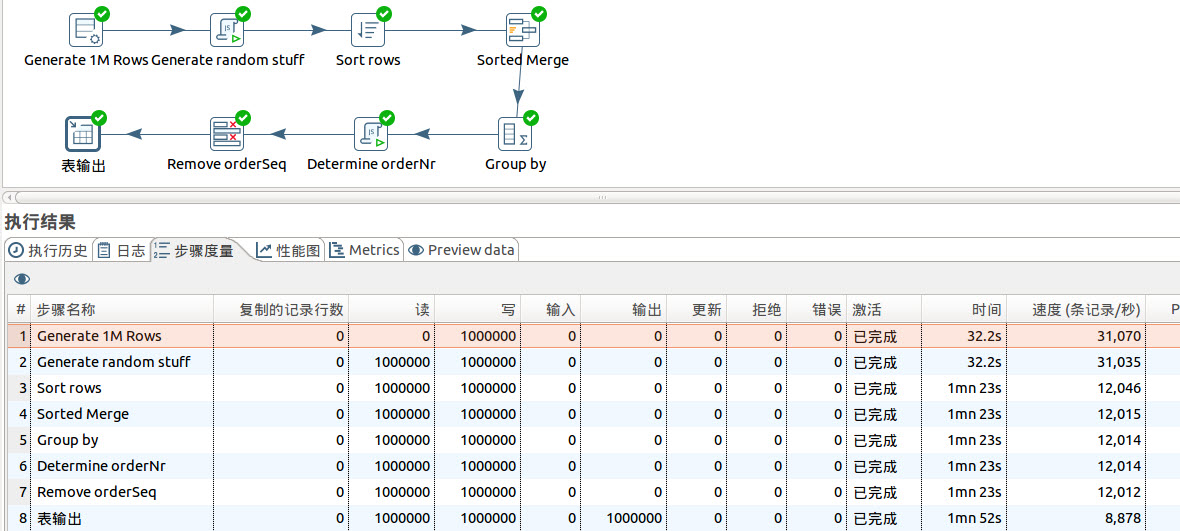
3. 数据同步
3.1 制作转换文件,
分别添加两个表输入mypostgres01和mypostgres02,然后再添加合并记录和数据同步。
数据库连接设置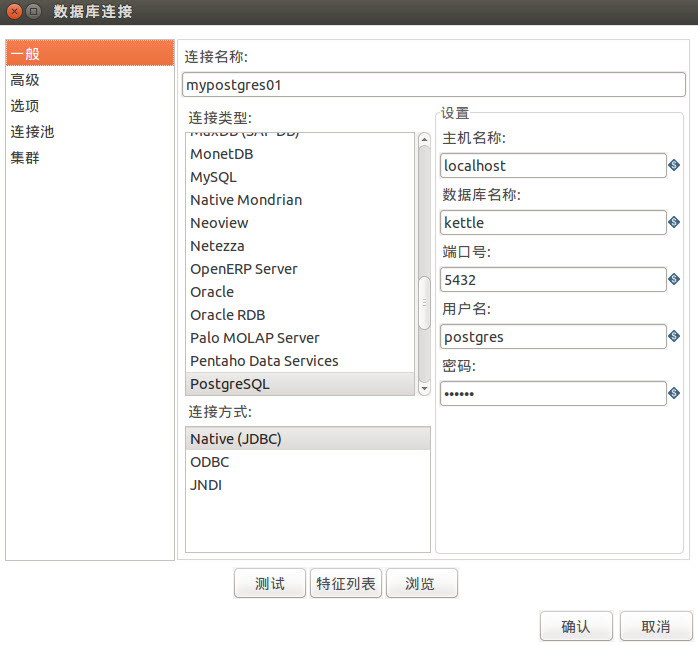
合并记录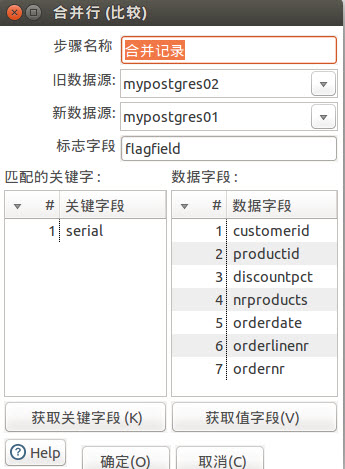
数据同步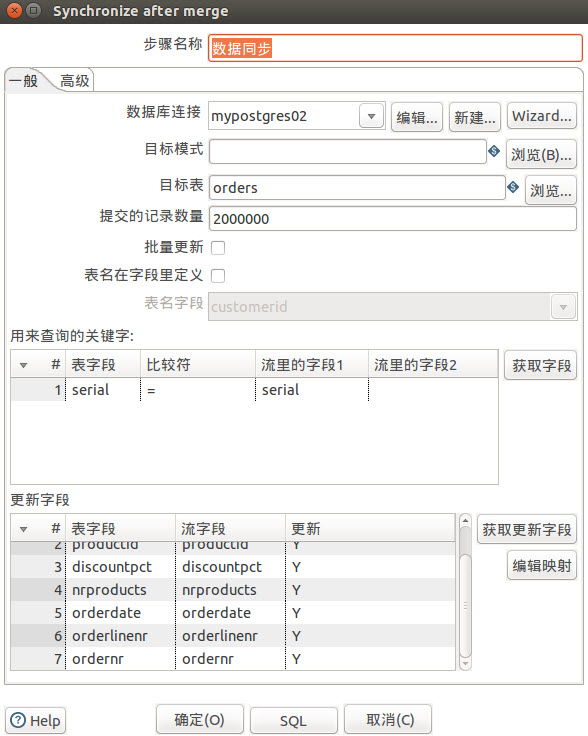
高级设置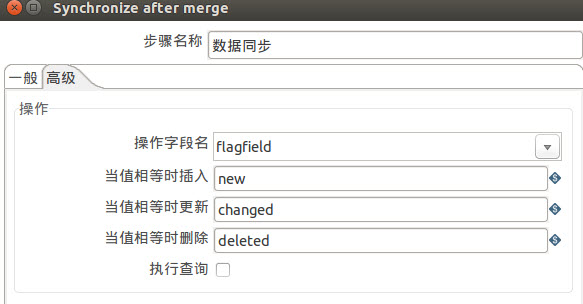
运行结果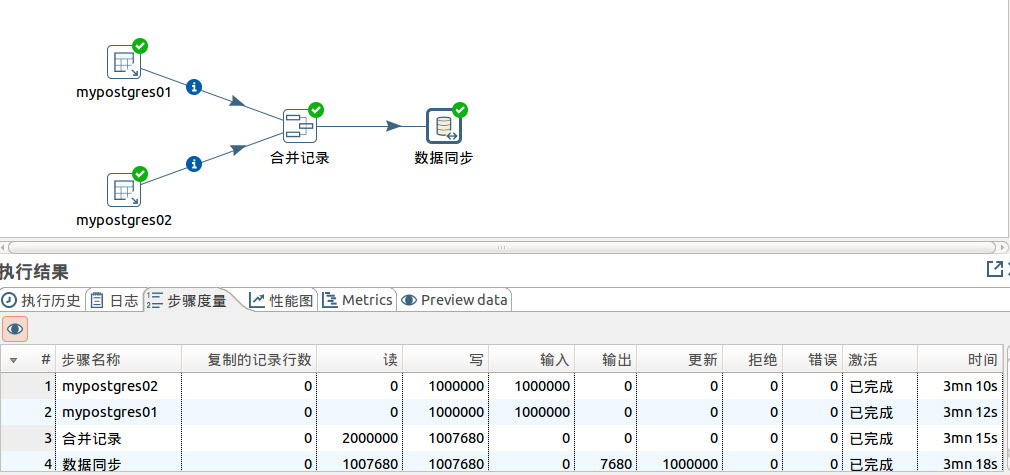
3.2 优化转换文件。
我们在合并前增加排序步骤。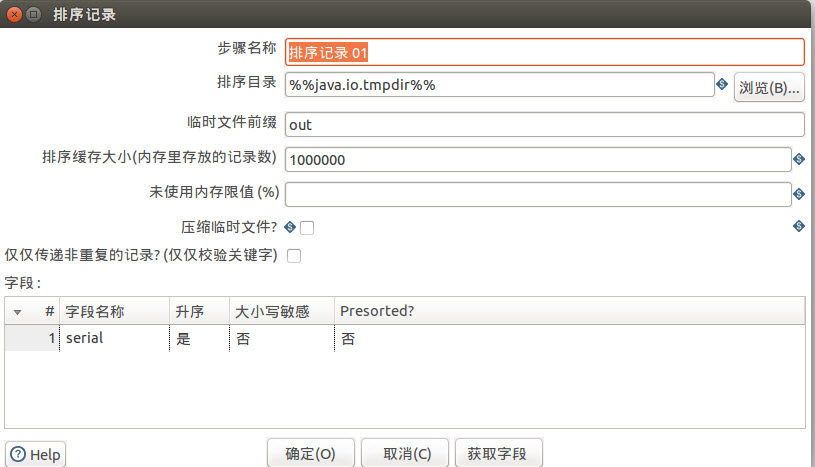
运行结果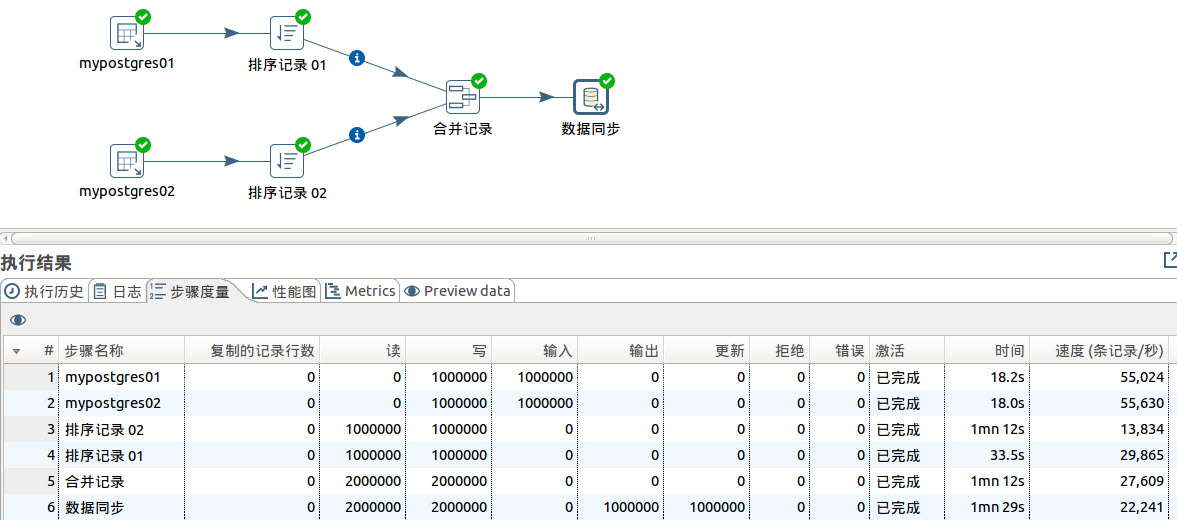
我们看到通过排序,数据同步完成时间由原来的3分多钟缩短到1分多钟,系统的性能大大提高。